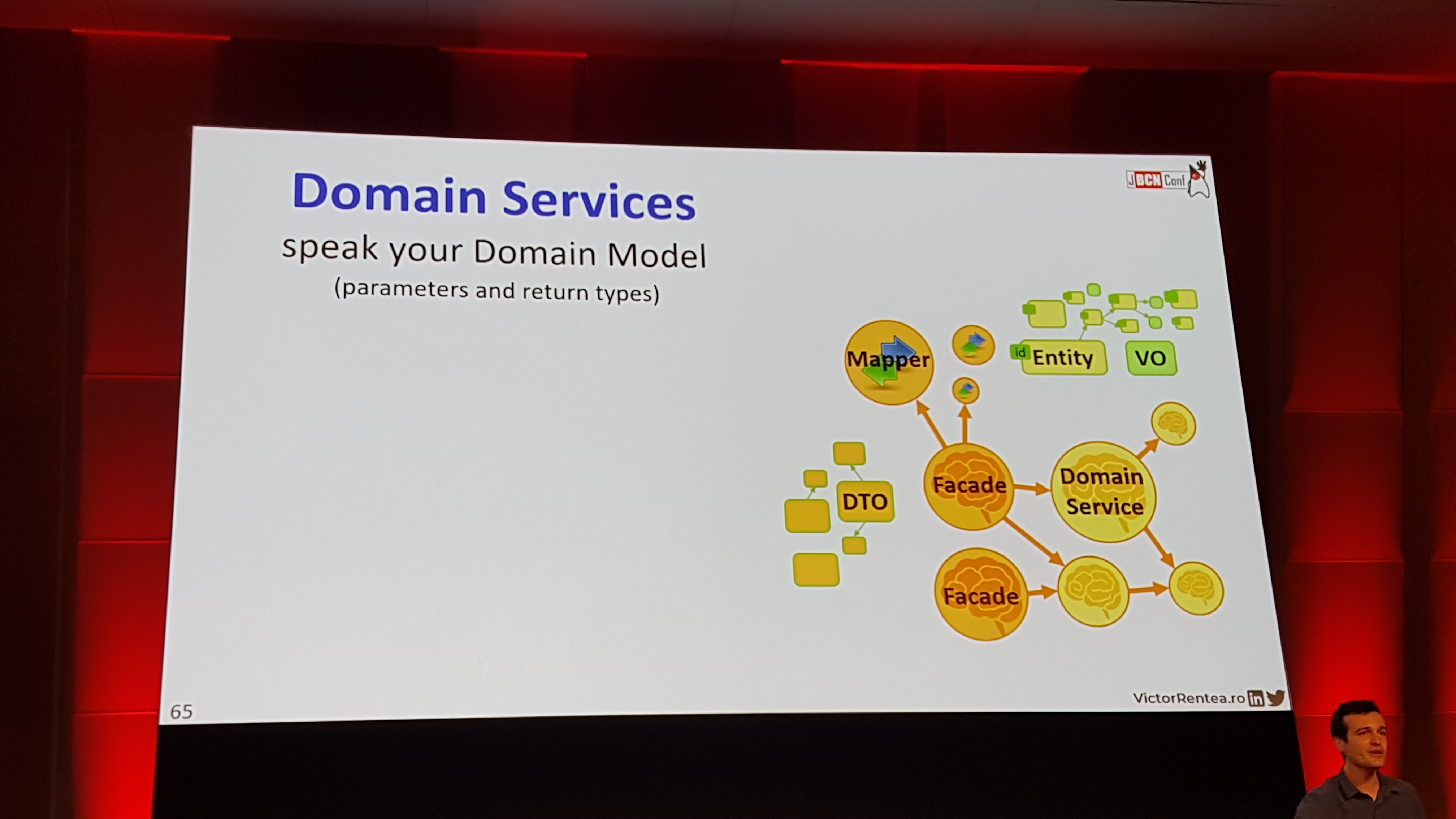
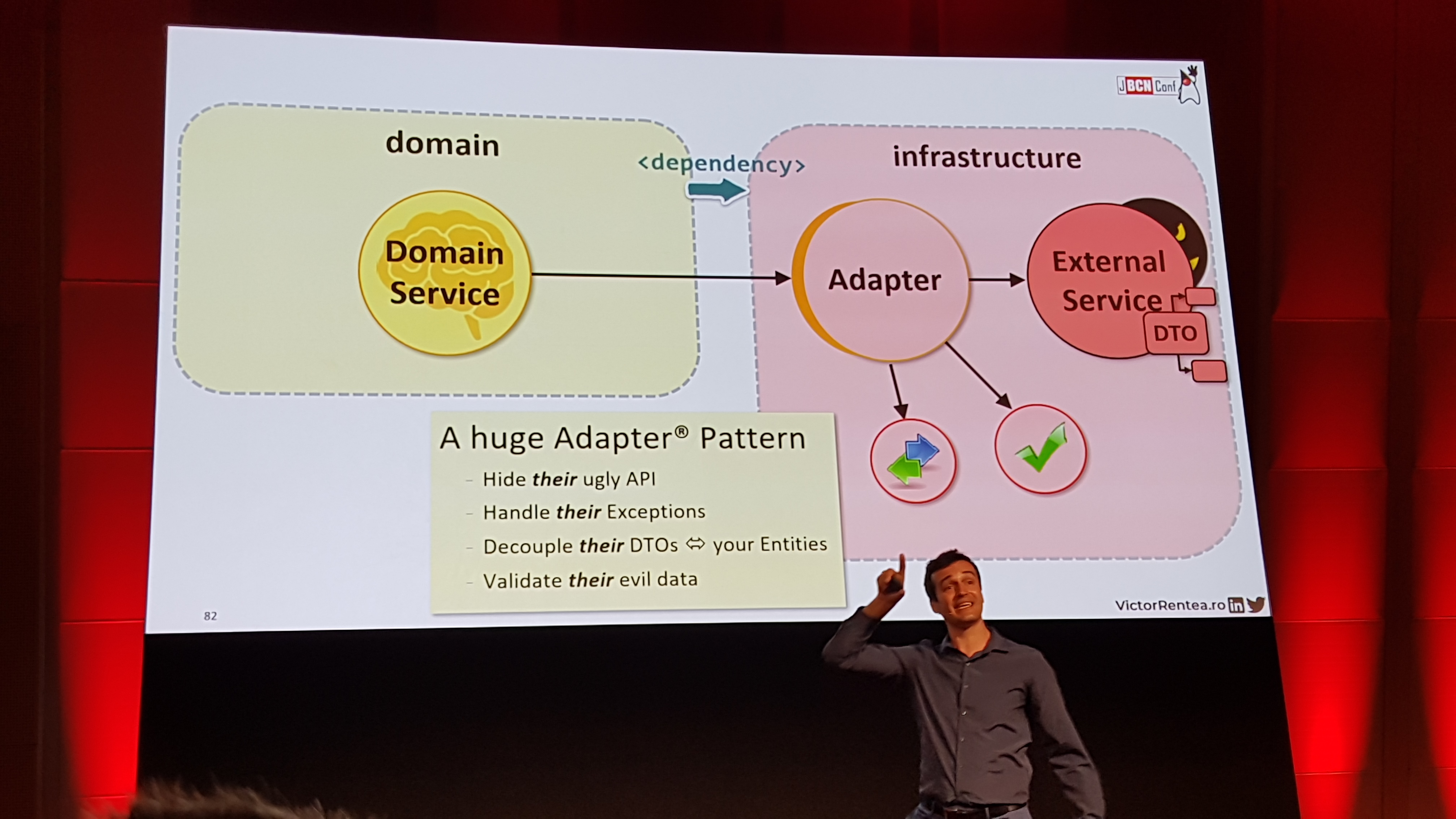
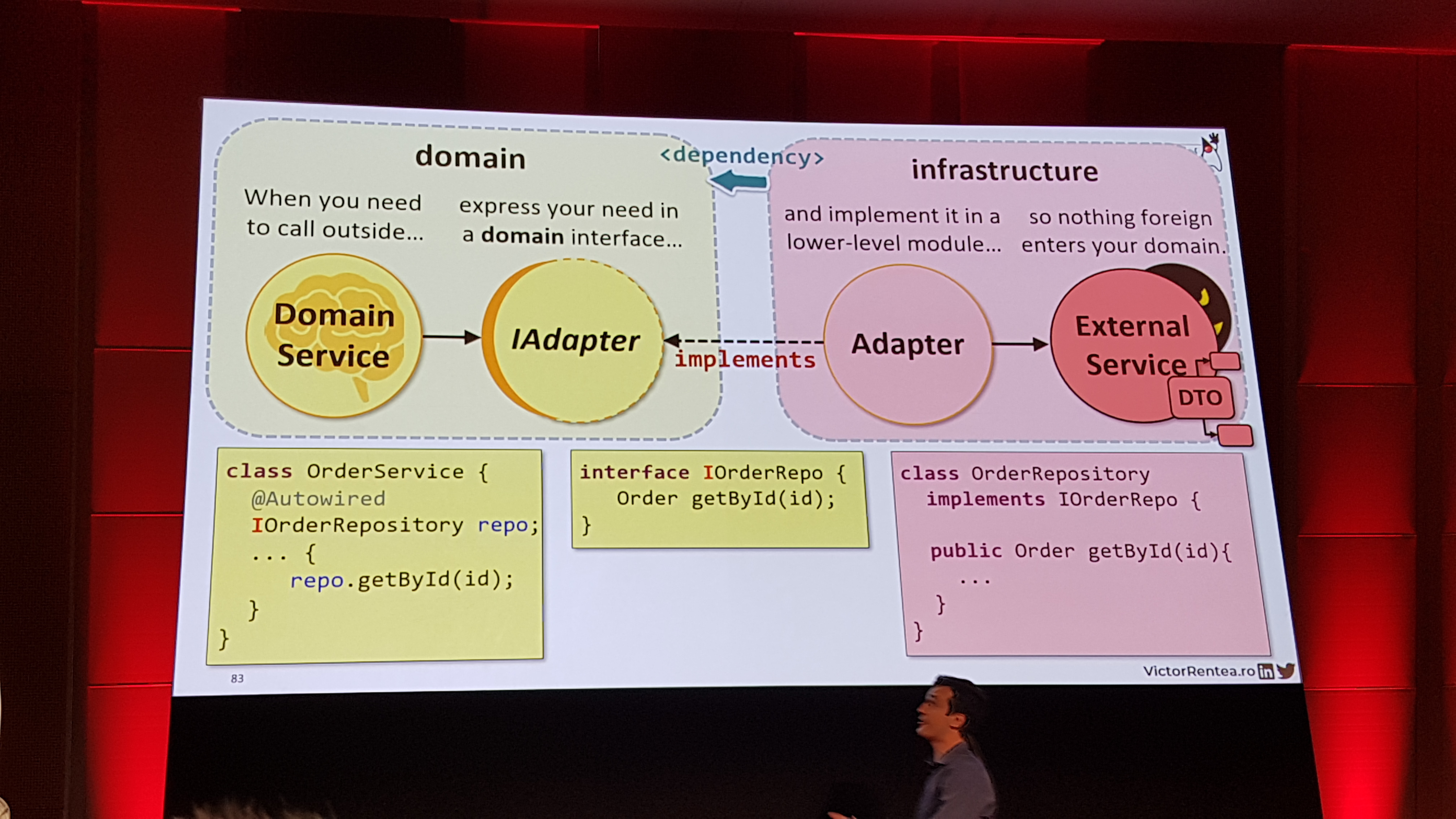
David RomeroSoftware EngineerFor several years I have a hard goal. I want to become a great software engineer, so I work hard developing quality software every day. Fan of new technologies. I will not stop until overcome my goals.
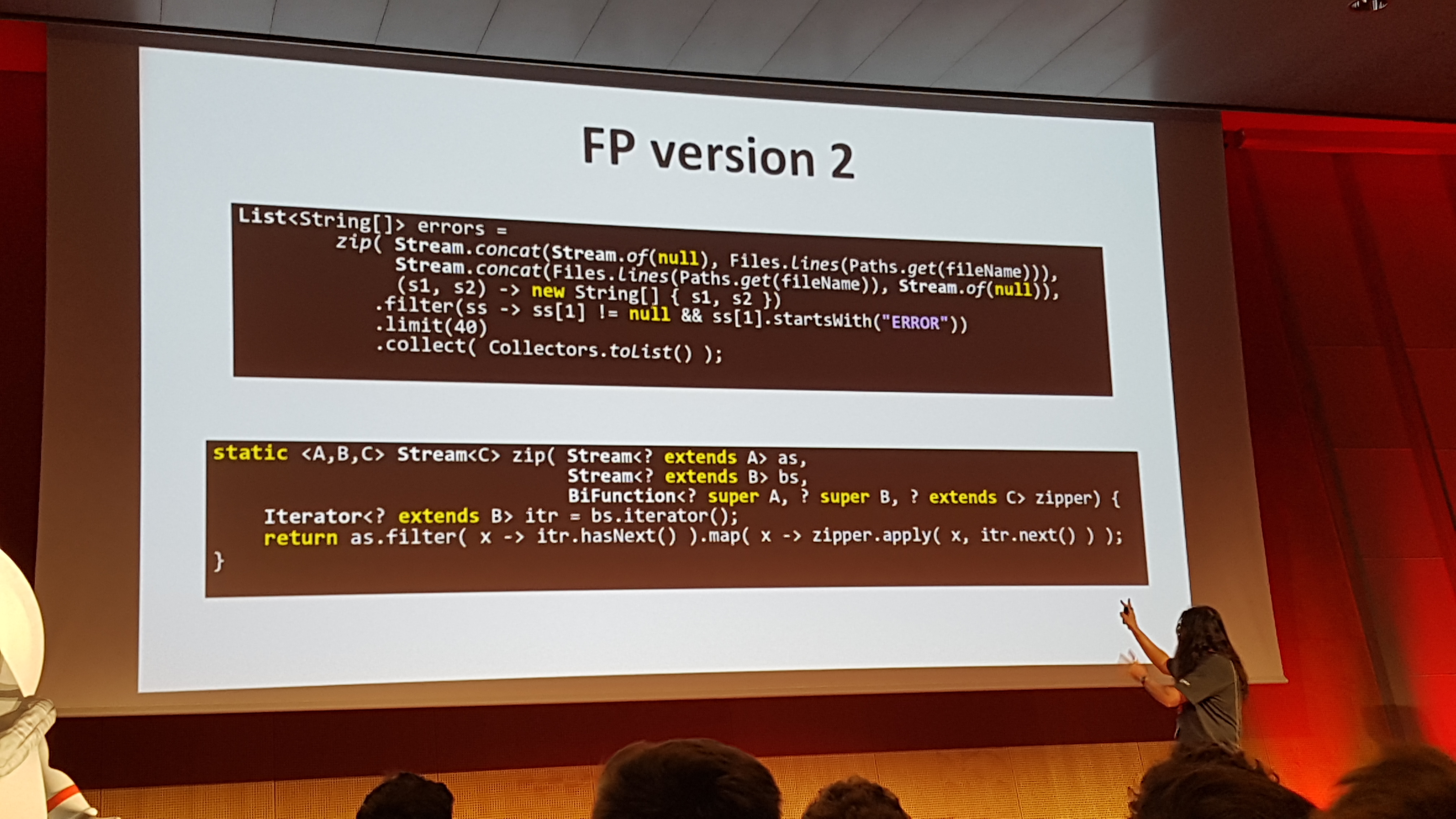
And, how to test the above code to verify that the output of the function returns the desired result?
Effectively, using mocks.
it("should include the time and message when marked as failed"){valitem=ItemBuilder().succeeded().build()implicitvalclock=mock[Clock[IO]]clock.realTime(*)returnsFTimeUnit.NANOSECONDS.convert(50,TimeUnit.SECONDS)valfailedItem=item.failed(newRuntimeException("Test error")).unsafeRunSync()failedItem.stateshouldBeEXCEPTIONvalerror=failedItem.errorerror.messageshouldBe"Test error"error.dateTimeshouldBeLocalDateTime.from(Instant.ofEpochSecond(50).atZone(ZoneId.systemDefault()))}
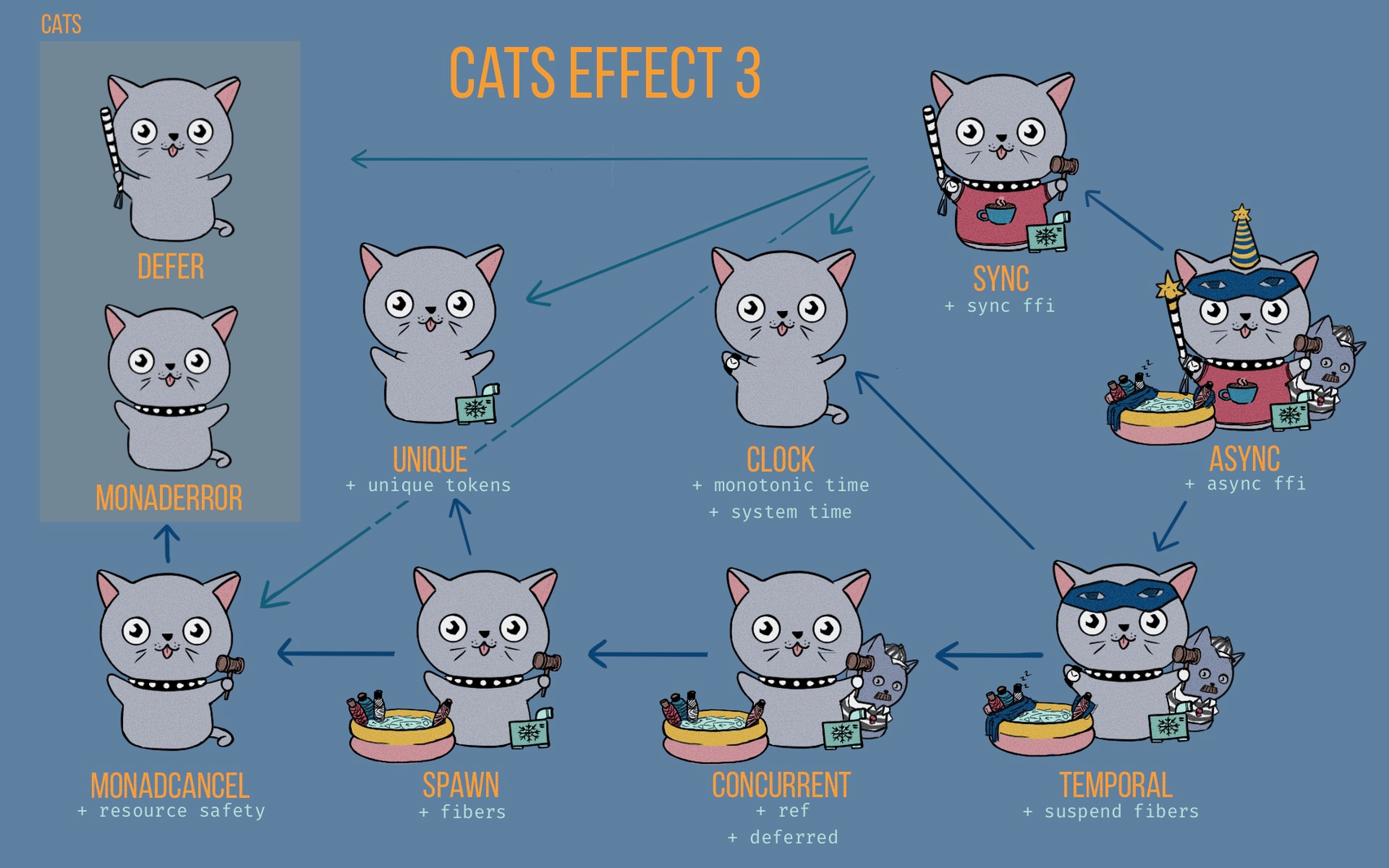
Migrating to Cats Effects 3
Now, Let’s go to check how to use the Clock type class with the new version of the library.
The looks quite similar but with a significant change, the Clock type class is not present in the bounded context.
Now, we have the problem, How I can inject a mocked clock?
Cats Effects provide a runtime that can be mocked to use with fibers, callbacks, and time support.
You need to add the following dependency to take advantage of this feature:
libraryDependencies += "org.typelevel" %% "cats-effect-testkit" % "3.3.7" % Test
With the TestControl class, you can “advance in the time” so, taking this into account, if you go to a certain period of time and use the Clock[F].realTimeInstant, in fact, we are mocking a timer.
Let’s check an example:
Scenario 1:
Given an item, when the item is purchased, an event should be published.
privatevalduration:FiniteDuration=FiniteDuration(Instant.parse("2021-01-01T00:00:00Z").toEpochMilli,TimeUnit.MILLISECONDS)it("should publish an ItemPurchased event"){//givenvalitem=anItem()valexpected=itemPurchasedEvent(item)gateway.doRequest(item)returnsFitem.asRight[Throwable]eventPublisher.publish(expectedEvent)returnsF(())//when(TestControl.execute(subject.doPurchase(item))flatMap{control=>for{_<-control.advanceAndTick(duration)_<-IO{//theneventPublisher.publish(expectedEvent)wascalled}}yield()}).unsafeRunSync()}
We’ll put the focus on the lines after the //when
Decorate our subject or program with the test runtime provided by Cats.
We have the power to do a journey through time. We are going to travel to 2021-01-01T00:00:00Z
Add an assert wrapped into the IO context since we are using the IO context in the whole test.
Execute the subject or program plus the time journey plus the assert.
The main aspect to take into account is the TestControl class and the adavanceAndTick function.
Okay, that seems a little verbose but okay, we can test our code to verify that an external component is invoked.
But now, let’s go further and verify the output of a function.
Scenario 2:
Given an item, when the item is purchased, it should return the purchased item
privatevalduration:FiniteDuration=FiniteDuration(Instant.parse("2021-01-01T00:00:00Z").toEpochMilli,TimeUnit.MILLISECONDS)privatevalkleisli=new(Id~>IO){defapply[E](e:E):IO[E]=IO.pure(e)}it("should return a confirmed item"){//givenvalitem=anItem()valexpected=itemPurchasedEvent(item)valconfirmedItem=item.confirmed()gateway.doRequest(item)returnsFitem.asRight[Throwable]eventPublisher.publish(expectedEvent)returnsF(())//when(TestControl.execute(subject.doPurchase(item))flatMap{control=>for{_<-control.advanceAndTick(duration)item<-control.results_<-IO{//thenitem.value.mapK(kleisli).embed(IO.pure(item.failed(TestingPurposeError)))shouldBeIO.pure(confirmedItem)}}yield()}).unsafeRunSync()}
We’ll put the focus on the lines after the // when
Decorate our subject or program with the test runtime provided by Cats.
We have the power to do a journey through time. We are going to travel to 2021-01-01T00:00:00Z
Obtain the result of our subject. The type of the item variable is Option[Outcome[Id, Throwable, Item]]
Line 20: The magic is here: I’m going to describe each operation step by step.
Extract the value of the Option using OptionValues trait.
Using Kleisli, map the monad from Id to IO since we are using IO.
At this point, we have the following type: Outcome[IO, Throwable, Item] and we want to extract the Item object. The Outcome type class is designed to model fibers execution status.
sealedtraitOutcome[F[_], E, A]finalcaseclassSucceeded[F[_], E, A](fa:F[A])extendsOutcome[F, E, A]finalcaseclassErrored[F[_], E, A](e:E)extendsOutcome[F, E, A]finalcaseclassCanceled[F[_], E, A]()extendsOutcome[F, E, A]
The Outcome type class provides an embed function with the aim of returning the result of the fiber or a fallback provided just in case the fiber is canceled. So, with the following statement: item.value.mapK(kleisli).embed(IO.pure(item.failed(TestingPurposeError))) we are extracting the item from the fiber result wrapped into IO.
The final step is to add an assert to verify that the output is the desired one.
TL;DR
Using TestControl.execute(F[A]) and control.advanceAndTick(duration) you can mock the time of the test execution.
The test is decorated with an IO, so you have to execute unsafeRunSync at the end of the TestControl statement.
To extract the value from the fiber could be a little tedious and verbose. item.value.mapK(kleisli).embed(IO.pure(item.failed(TestingPurposeError)))
In the same way that in the last years, I’m going to make a retrospective of my year reviewing my goals and checking if I fulfilled my objectives.
The first step is to review the year in a personal and professional way and if I have met the goals that I set for myself.
Here we go with my 2020’s summary.
2020 was a pandemic year so, all my plans blew up, and I had to change my mind and take a step-by-step approach.
I managed to finish a marathon.
I started a new step in my career working at Packlink.
I moved to Aracena, Spain, my home town.
I’ve been working from home since February.
Now, time to review the goals
Learn English seriously. In Progress I have not been able to fulfill this objective, however, I’m attending twice a week to English lessons, so even though my English level has not improved, I’m training several times in the week with a great teacher which allows me to improve my English level. Besides, in Packlink, I have a lot of coworkers who speak in English, so I’m training a lot, and I hope to have major progress this year.
Read books Done! Great job with this goal! More than ten books per year is a great number. I know that reading one book every month is not an impressive number but for me, it’s a great stride.
Contribute to an open-source project. In Progress This aim has not been completed at 100 % but I have done huge improvements. I’ve been researching some open source projects in order to learn how to contribute and besides, I’ve released my first library which integrates Cucumber & Micronaut. cucumber-micronaut
Publish at least six posts. To-Do This year has been very difficult in mental strength so, I wasn’t able to publish any post to the blog.
With the lesson learned from last year and what I want to be in 2021, these are my goals for the new year.
Learn English seriously. This goal has to be the most important in 2021 again, I must learn as much as possible. I think I have had major progress that I must strengthen and maintain in 2021. Furthermore, I should complete this goal in order to be comfortable in Packlink, so this is a must-have.
Contribute to an open-source project & maintain cucumber-for-micronaut library The most beautiful goal. One of my ambitions in my professional life. I want to contribute to one of the most famous open-source projects like Spring Framework, Jenkins, Elastic, etc… There are a lot of issues labeled as good for beginners so I have to research in the GitHub repositories and contribute to those projects. I would like to solve all issues in my library and release new versions with new features.
Publish at least six posts My blog was the great forgotten last year, and therefore I have to resume this beautiful task. Maybe, I could post my progress with Scala and some recaps of the books that I read.
Take advantage of working from home I enjoy widely working from home and having time for myself, so I should take advantage of this opportunity.
From a personal point of view, I’m working from home 100 %, so I have to improve my communication skills, and my productivity to take advantage of this amazing opportunity.
In the same way that in the last three years, I’m going to make a retrospective of my year reviewing my goals and checking if I fulfilled my objectives.
The first step is to review the year in a personal and professional way and if I have met with the goals that I set to myself.
Here we go with my 2019’s summary.
2019 was a strange year with some changes in my personal and professional life. It was a year with a lots of ups and downs but with a successful outcome.
I managed to finish a half-marathon
My team has grown to six members. One year ago, we were a two-member team.
My health is so good.
Now, time to review the goals
Learn English seriously. In Progress I have not been able to fulfill this objective, however, I’m attending twice a week to English lessons, so even though my English level has not improved, I’m training several times in the week with a great teacher which allow me to improve my English level
Read books Done! Great job with this goal! More than six books per year is a great number. I know that reading one book every two months is not an impressive number but for me it’s okay.
Attend conferences and improve the nertworking. Done! Another good news, In 2019 I attended two important conferences in the software world at the national level. In June I attended the JBCNConf and in November I attended the Commit Conf. Besides, my networking has improved in the JBCNConf since I attended to the networking party. https://twitter.com/davromalc/status/1133089820455120896
Give a talk or workshop. Done! The best job! It has been a positive surprise of the year. I gave my first talk as the main speaker and it was a great success. 48 attendees and incredible feedback received was the result of the talk. Even several interactions on twitter with my personal account or my company’s account.
I was astonished by the result of my talk and I was very happy. On the other hand, It was a very hard job and I think it’s difficult for me to give a talk like that in the future.
With the lesson learned from last year and what I want to be in 2020, these are my goals for new year.
Learn English seriously. This goal has to be the most important in 2020 again, I should get a certification higher than the one I already have to keep the progress I’ve had since last year. I must learn as much as possible. I think I have had a very good progress that I must strengthen and maintain in 2020.
Contribute to an open source project The most beautiful goal. One of my ambitions in my professional life. I want to contribute to one of the most famous open-source projects like Spring Framework, Jenkins, Elastic, etc… There are a lot of issues labeled as good for beginners so I have to research in the GitHub repositories and contribute to those projects.
Read books. Last year I read 6 books, so this year I have to read even more. I should combine personal and professional books. I have to keep the same pace.
Publish at least six posts My blog was the great forgotten last year, and therefore I have to resume this beautiful task.
Besides, I have an astonishing goal this year: Run a marathon. In detail, I’m going to run the Seville marathon the next February. This goal is one of the most important challenges that I will deal with it and it’s the goal that more enthusiasm produces to me.
Instead of reviewing these objectives annually, perhaps I should review these objectives quarterly.
I’ve just finished the book ‘The Senior Software Engineer’ of David Bryant, and I think is a really good book for any software developer who wants to know what really seniority means. Some developers think that to be a senior software engineer is related to the years that he or she is has been working in software engineering and I have always thought that this concept is a mistake. David Bryant thinks the same than me, and besides, he proposes several capabilities that a real senior software engineer must have.
In the first chapter, the author explains to the reader one of the most important topics in the book: How to focus on delivering results. This topic is the guiding theme of the book and one of the most important capabilities that a software engineer should have, in my humble opinion. Focus on delivering results is a very interesting chapter in which, the author shows to the reader with hands-on experience what are the results, and how to manage it.
It’s not my intention, to write a recap of each chapter. However, I would like to highlight some chapters or sections that I’ve been very impressed by the content and the main concepts. Therefore, I will outline these sections in the following list.
In the chapter ‘Add new features with ease’, the author introduces a diagram whereby the flow to develop a new feature is explained step by step. I have to admit that this flow diagram is one of the concepts that I most like in the book.
This flow diagram, is a mix between TDD and developing good acceptance test and, as a summarize, it’s more or less as follow:
In the middle of the book, the reader is taught about how to make a techincal decision. In this chapter, I’ve taken note of two main ideas since this is a weak point of mine.
Facts, priorities and conclusions. Making a decision about what solution to use can be difficult; programmers are an opinionated bunch. Therefore, when you are making a decision, at a high level, you must identify facts (as distinct from opinions), identify your priorities (as well as the priorities or other) and then combine the two in order to make your decision or put forth your argument.
Falacies. Making decisions based on fallacies can create problems later on and fallacies have a way of cropping up in many debates. The author exposes some of the main fallacies existing in the software engineering like hasty generalization, correlation does not imply causation, false equivalence or appeal to authority.
In the following chapter, ‘Bootstrap Greenfield Systems’, I would like to highlight a new term, for me at least, MDS or minimum deployable system. This section explains that once you have made the required technical decisions and the ecosystem has been established, you must focus on deploying your system as fast as possible to production. When the system has been deployed, developers can add new features more easily and that features can be deployed and delivered more quickly than if you had started developing features at the beginning and leaving the deployments for later.
In my humble opinion, this idea should be taken into account whenever possible and particularly in the projects that continuous deployment cannot be performed.
One of the aspects that generates the most controversy among the technical leaders is how to make effective technical interviews. In the ninth chapter, David Bryant explains how the ideal technical interview should be with a step by step process:
Informal technical discussion to meet and get to know the candidate
Have the candidate do a “homework assignment”
Conduct a technical phone screen.
Pair program with the candidate person.
___
Although this process may look very difficult and very hard, after some bad experiences, I think this procedure is a really good approach for making a technical interview. The homework is a good filter and an assurance about the candidate who will be interviewed in person. Moreover, a pair programming session is one of the best techniques to exchange views on any technical debate.
In one of the final chapters, the author teaches the reader how to be more productive. Being honest, I have to put emphasis on this capability. For this assignment, I would like to highlight the improved graph of the chapter ‘Add features with ease’ to the which, the author has added when to do long and short breaks in order to manage better the email or answering some chat without losing the focus.
In this flow diagram, the author has added the breaks concisely to fit with the stages in which a developer need a short break, like when in the TDD cycle, a unit test is passing or a longer break, like when the code is refactored. Besides, He stipulates the stages in which a break is not allowed like when a developer is writing a unit test or when a developer is cleaning up the code.
At the end of the book, the author gives several tips about how to lead a team. In particular, I would like to stress in the section ‘General tips on Reviewing code’.
As a senior software engineer, you have to review code every day and being a great code reviewer is a great capability that your team will appreciate. The following tips will help you to do a great code reviews:
Read the entire changeset before commenting on it.
Speak about the code, not the coder
If you don’t understand something, ask
Approach style-related issues tactfully.
Don’t be afraid to have a real-time conversation
Convey this information to others.
Interacting with QA.
Interacting with a Security Team.
To sum up, the senior software engineer is a great book in which capabilities that a senior software engineer must have are been explained, and besides, several techniques for improving your daily work. I’ve learned a lot of useful concepts and ideas that I’m already applying in my current job that has helped me to improve my performance. I would like to recommend this book to every software engineer, not only junior developers but also to more experienced developers since it offers some valuable guidelines for everyone who wants to improve its capabilities and to be a better software engineer.
Last Monday, May 27, began the JBCNConf in Barcelona one of the biggest and important conference about the JVM in Spain.
I went as attendee and enjoyed the talks very much.
As I couldn’t go to all of them, I’ve been looking for the slides of all the talks so I can save them and read them with ease.
Below I will list all the ones I found or I attended.
Besides, I’ll attach some pictures that I taken in some talks.
This post is becoming a tradition in my blog as I have been writing for the last three years. The first time I wrote it was because I saw David Bonilla’s post with his year purposes and it seemed to me a very good practice of retrospective and review for my personal goals.
Following in the steps of David Bonilla, I will start by reviewing how the past 2018 was for me and if I have met the goals that I set myself.
Here we go with my 2018’s summary.
Learn English seriously. In Progress Although I have not been able to fullfill this objective, I think I can also be happy as I have managed to obtain an English level certification in Cambridge, something that seemed far in the past. It’s true that I’m still not at the desired level but working hard every year I’ll get the milestone sooner.
Lead a healthier life. Done! It has been the positive surprise of the year since I have achieved to lead a much healthier life, lose weight and be less stressed. Maybe this goal will not be on the list for 2019 but I must never forget it.
Attend conferences, talks and events related to the software. Done! Another good news, In 2018 I attended two important conferences in the software world at the national level. In June I attended the JBCNConf and in November I attended the Commit Conf. This events were awesome, besides, I enjoyed and learned a lot and I would like to go again in the next year.
Get a certification Because I have focused on other goals such as studying English or attending events, this goal has been the forgotten one of 2018. Right now it does not motivate me much.
On a personal level, I’m happy since I have published twice as many articles as last year in this blog and I have also given my first talk at a professional level.
With the lesson learned from last year and what I want to be in 2019, these are my goals for new year.
Learn English seriously. This goal has to be the most important in 2019 again, I should get a certification higher than the one I already have to keep the progress I’ve had since last year. I must learn as much as possible. I think I have had a very good progress that I must strengthen and maintain in 2019.
Read books. I have bought some technical books during the last two years and I have only managed to finish one. Therefore, for this new year as a goal I must have read at least three books.
Attend conferences and improve the nertworking. Following the trend of 2018, I must continue attending conferences related to the software and not stay there. I have to do networking since I can know great professionals and great people in these events.
Give a talk or workshop. I think this could be a great goal for this new year and that it can give me a new way in my professional career. I have always liked to teach others everything I know and maybe this is another way to do it.
Instead of reviewing these objectives annually, perhaps I should review these objectives quarterly. I will check it throughout the year.
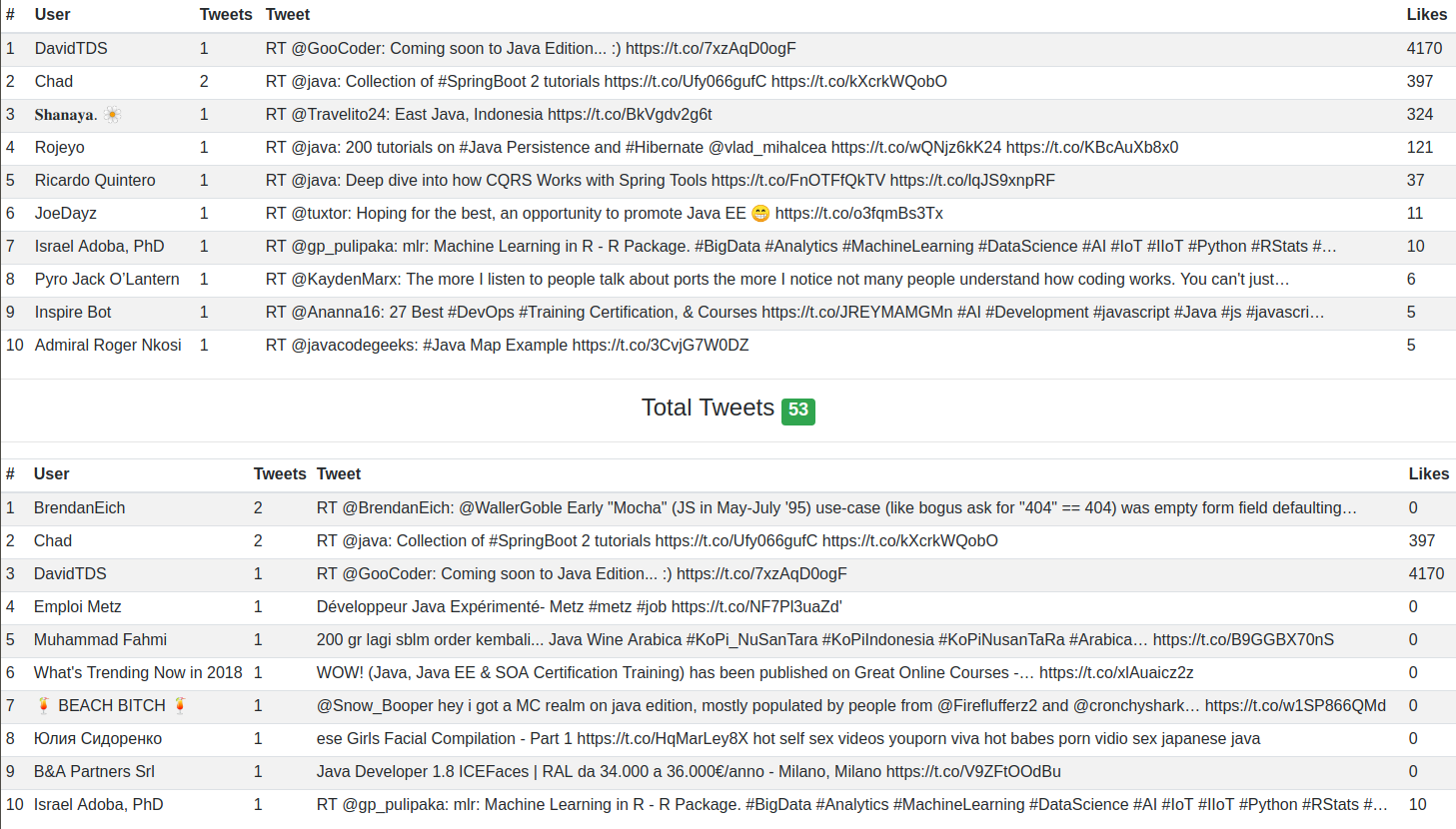
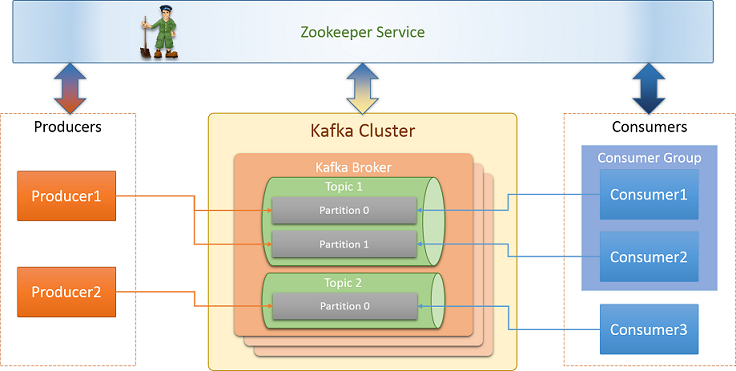
Last September, my coworker Iván Gutiérrez and me, spoke to our cowokers how to implement Event sourcing with Kafka and in this talk, I developed a demo with the goal of strengthen the theoretical concepts. In this demo, I developed a Kafka Stream that reads the tweets containing “Java” word from Twitter, group tweets by username and select the tweet with the most likes. The pipeline ends sending the recolected information to PostgreSQL
As we have received positive feedback and we have learned a lot of things, I want to share this demo in order to it will be available to anyone who wants to take a look.
The demo is an implementaiton of the CQRS pattern based on Kafka and Kafka Streams. As we can see in the main image, Kafka is able of decoupling read (Query) and write (Command) operations, which helps us to develop event sourcing applications faster.
The Stack
The whole stack has been implemented in Docker for its simplicity when integrating several tools and for its isolation level.
The stack is composed of
version:'3.1'services:############## Kafka#############zookeeper:image:confluentinc/cp-zookeepercontainer_name:zookeepernetwork_mode:hostports:-"2181:2181"environment:ZOOKEEPER_CLIENT_PORT:2181kafka:image:confluentinc/cp-kafkacontainer_name:kafkanetwork_mode:hostdepends_on:-zookeeperports:-"9092:9092"environment:KAFKA_ZOOKEEPER_CONNECT:localhost:2181KAFKA_ADVERTISED_LISTENERS:PLAINTEXT://localhost:9092KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR:1# We have only 1 broker, so offsets topic can only have one replication factor.connect:image:confluentinc/cp-kafka-connectcontainer_name:kafka-connectnetwork_mode:hostports:-"8083:8083"depends_on:-zookeeper-kafkavolumes:-$PWD/connect-plugins:/etc/kafka-connect/jars# in this volume is located the postgre driver.environment:CONNECT_BOOTSTRAP_SERVERS:kafka:9092CONNECT_REST_PORT:8083# Kafka connect creates an endpoint in order to add connectorsCONNECT_REST_ADVERTISED_HOST_NAME:"kafka-connect"CONNECT_GROUP_ID:kafka-connectCONNECT_ZOOKEEPER_CONNECT:zookeeper:2181CONNECT_CONFIG_STORAGE_TOPIC:kafka-connect-configCONNECT_OFFSET_STORAGE_TOPIC:kafka-connect-offsetsCONNECT_STATUS_STORAGE_TOPIC:kafka-connect-statusCONNECT_CONFIG_STORAGE_REPLICATION_FACTOR:1# We have only 1 broker, so we can only have 1 replication factor.CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR:1CONNECT_STATUS_STORAGE_REPLICATION_FACTOR:1CONNECT_KEY_CONVERTER:"org.apache.kafka.connect.storage.StringConverter"# We receive a string as key and a json as valueCONNECT_VALUE_CONVERTER:"org.apache.kafka.connect.json.JsonConverter"CONNECT_INTERNAL_KEY_CONVERTER:"org.apache.kafka.connect.storage.StringConverter"CONNECT_INTERNAL_VALUE_CONVERTER:"org.apache.kafka.connect.json.JsonConverter"CONNECT_PLUGIN_PATH:/usr/share/java,/etc/kafka-connect/jars############## PostgreSQL#############db:container_name:postgresqlnetwork_mode:hostimage:postgresrestart:alwaysports:-"5432:5432"environment:POSTGRES_DB:influencersPOSTGRES_USER:userPOSTGRES_PASSWORD:1234
Kafka: The main actor. You need to set zookeeper ip. You can see all proficiencies in the provided slides above.
Kafka Connector: One of the 4 main Kafka core API. It’s in charge of reading records of a provided topic and inserting them into PostgreSQL.
PostgreSQL: SQL Database.
Producer
It’s the writer app. This piece of our infrastructure is in charge of read the tweets containing “Java” word from Twitter and send them to Kafka.
The following code has two sections: Twitter Stream and Kafka Producer.
Twitter Stream: Create a data stream of tweets. You can add a FilterQuery if you want to filter the stream before consuption. You need credentials for accesing to Twitter API.
Kafka Producer: It sends records to Kafka. In our demo, it sends records without key to the ‘tweets’ topic.
@SpringBootApplication@Slf4jpublicclassDemoTwitterKafkaProducerApplication{publicstaticvoidmain(String[]args){// Kafka configPropertiesproperties=newProperties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");//Kafka cluster hosts.properties.put(ProducerConfig.CLIENT_ID_CONFIG,"demo-twitter-kafka-application-producer");// Group idproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());Producer<String,String>producer=newKafkaProducer<>(properties);// Twitter StreamfinalTwitterStreamtwitterStream=newTwitterStreamFactory().getInstance();finalStatusListenerlistener=newStatusListener(){publicvoidonStatus(Statusstatus){finallonglikes=getLikes(status);finalStringtweet=status.getText();finalStringcontent=status.getUser().getName()+"::::"+tweet+"::::"+likes;log.info(content);producer.send(newProducerRecord<>("tweets",content));}//Some methods have been omitted for simplicity.privatelonggetLikes(Statusstatus){returnstatus.getRetweetedStatus()!=null?status.getRetweetedStatus().getFavoriteCount():0;// Likes can be null.}};twitterStream.addListener(listener);finalFilterQuerytweetFilterQuery=newFilterQuery();tweetFilterQuery.track(newString[]{"Java"});twitterStream.filter(tweetFilterQuery);SpringApplication.run(DemoTwitterKafkaProducerApplication.class,args);Runtime.getRuntime().addShutdownHook(newThread(()->producer.close()));//Kafka producer should close when application finishes.}}
This app is a Spring Boot application.
Kafka Stream
The main piece of our infrastructure is in charge of read the tweets from ‘tweets’ topics, group them by username, count tweets, extract the most liked tweet and send them to the ‘influencers’ topic.
Let’s focus on the two most important methods of the next block of code:
stream method: Kafka Stream Java API follow the same nomenclature that the Java 8 Stream API. The first operation performed in the pipeline is to select the key since each time the key changes, a re-partition operation is performed in the topic. So, we should change the key as less as possible. Then, we have to calculate the tweet that most likes has accumulated. and as this operation is a statefull operation, we need to perform an aggregation. The aggregation operation will be detailed in the following item. Finally, we need to send the records to the output topic called ‘influencers’. For this task we need to map Influencer class to InfluencerJsonSchema class and then, use to method. InfluencerJsonSchema class will be explained in Kafka Connector section. Peek method is used for debugging purposes.
aggregateInfoToInfluencer method: This is a statefull operation. Receives three args: the username, the raw tweet from the topic and the previous stored Influencer. Add one to the tweet counter and compare the likes with the tweet that more likes had. Returns a new instance of the Influecer class in order to mantain immutability.
@Configuration@EnableKafkaStreamsstaticclassKafkaConsumerConfiguration{finalSerde<Influencer>jsonSerde=newJsonSerde<>(Influencer.class);finalMaterialized<String,Influencer,KeyValueStore<Bytes,byte[]>>materialized=Materialized.<String,Influencer,KeyValueStore<Bytes,byte[]>>as("aggregation-tweets-by-likes").withValueSerde(jsonSerde);@BeanKStream<String,String>stream(StreamsBuilderstreamBuilder){finalKStream<String,String>stream=streamBuilder.stream("tweets");stream.selectKey((key,value)->String.valueOf(value.split("::::")[0])).groupByKey().aggregate(Influencer::init,this::aggregateInfoToInfluencer,materialized).mapValues(InfluencerJsonSchema::new).toStream().peek((username,jsonSchema)->log.info("Sending a new tweet from user: {}",username)).to("influencers",Produced.with(Serdes.String(),newJsonSerde<>(InfluencerJsonSchema.class)));returnstream;}privateInfluenceraggregateInfoToInfluencer(Stringusername,Stringtweet,Influencerinfluencer){finallonglikes=Long.valueOf(tweet.split("::::")[2]);if(likes>=influencer.getLikes()){returnnewInfluencer(influencer.getTweets()+1,username,String.valueOf(tweet.split("::::")[1]),likes);}else{returnnewInfluencer(influencer.getTweets()+1,username,influencer.getContent(),influencer.getLikes());}}@Bean(name=KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)publicStreamsConfigkStreamsConfigs(KafkaPropertieskafkaProperties){Map<String,Object>props=newHashMap<>();props.put(StreamsConfig.APPLICATION_ID_CONFIG,"demo-twitter-kafka-application");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,kafkaProperties.getBootstrapServers());props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG,Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());returnnewStreamsConfig(props);}}
@EnableKafkaStreams annotation and kStreamsConfigs method are the responsible of integrate the Kafka Stream API with Spring Framework.
Further information of this integration is provided here
In the above block of code is mentioned Influencer class and in order to facilitate the read, the code of Influencer class is provided here:
fromJson method is mandatory due to serialization proccess used by Kafka Stream. See Kafka Stream Serde if you want to know more about this topic.
This app is a Spring Boot application.
Kafka Connector
Once we have fed our topic ‘influencers’, we have to persist the data to Postgre. For this task, Kafka provide a powerful API called Kafka Connect. Confluent, the company created by Apache Kafka’s developers, has developed several connectors for many third-party tools. For JDBC, exits two connectors: source and sink. Source connectors reads data from jdbc drivers and send data to Kafka. Sink connectors reads data from Kafka and send it to jdbc driver.
We are going to use a JDBC Sink connector and this connector needs the schema information in order to map topic records into sql records. In our demo, the schema is provided in the topic record. For that reason, we have to map from Influecer class to InfluencerJsonSchema class in our data pipeline.
In the following code, you can see how the schema will be sent. If you want to see how is the result in json format you can see the provided gist.
Then, we need to configure our Kafka connector. Source topic, destination table, primary key or url connection should be provided.
Special mention for the field ‘insert.mode’. We use ‘upsert’ mode due to the primary key is the username so the records will be inserted or updated depending on whether the user has been persited before or not.
The above json code has been stored into a file in order to have a follow-up of it
Once we have developed the connector, we have to add the connector to our Kafka Connector container and this can be performed with a simple curl.
foo@bar:~$curl -i-X POST -H"Accept:application/json"-H"Content-Type:application/json" http://localhost:8083/connectors/ -d @connect-plugins/jdbc-sink.json
Reader App
We have developed a simple Spring Boot applications to read inserted records in Postgre. This app is very simple and the code will be skipped of this post since it does not matter.
Attached a screenshot of the UI in order to view the results.
If you want to see the code, is available in Github
3. How to run
If you want to run the demo you have to execute the following commands.
foo@bar:~$docker-compose up
foo@bar:~$curl -i-X POST -H"Accept:application/json"-H"Content-Type:application/json" http://localhost:8083/connectors/ -d @connect-plugins/jdbc-sink.json
foo@bar:~$mvn clean spring-boot:run -pl producer
foo@bar:~$mvn clean spring-boot:run -pl consumer
foo@bar:~$mvn clean spring-boot:run -pl reader
4. Conclusion
This demo show us a great example of a CQRS implementation and how easy it’s to implement this pattern with Kafka.
In my humble opinion, Kafka Stream is the most powerful API of Kafka since provide a simple API with awesome features that abstracts you from all the necessary implementations to consume records from Kafka and allows you to focus on developing robust pipelines for managing large data flows.
Besides, Spring Framework provides an extra layer of abstraction that allow us to integrate Kafka with Spring Boot applications.
The full source code for this article is available over on GitHub.
After a couple of months learning and researching about kafka streams, I wasn’t able to find much information about how to test my kafka streams so I would like to share how a kafka stream could be tested with unit or integration tests.
We have the following scenarios:
Bank Balance: Extracted from udemy. Process all incoming transactions and accumulate them in a balance.
Customer purchases dispatcher: Process all incoming purchases and dispatch to the specific customer topic informed in the purchase code received.
Menu preparation: For each customer, the stream receives several recipes and this recipes must be grouped into a menu and sent by email to the customer. A single email should be received by each customer
For the above scenarios, we have unit and/or integration tests.
Some dependencies, like junit, mockito, etc.. has been omitted to avoid verbosity
3. Unit tests
Unit tests for kafka streams are available from version 1.1.0 and it is the best way to test the topology of your kafka stream. The main advantage of unit tests over the integration ones is that they do not require the kafka ecosystem to be executed, therefore they are faster to execute and more isolated.
Let’s suppose that we have the following scenario:
We have a topic to which all the purchases made in our application and a topic for each customer. Each purchase has an identification code which includes the code of the customer who made the purchase. We have to redirect this purchase to the customer’s own topic. To know the topic related to each client we receive a map where the key will be the customer code and the value of the target topic.
Besides, we have to replace spanish character ‘ñ’ by ‘n’.
The driver configuration should be the same that we have in our kafka environment.
Once we have our TestDrive we can test our topology.
@Test@DisplayName("Given Ten Codes And A Map With Customer Codes And Target Topics When The Stream Receives Ten Codes Then Every Target Topic Should Receive Its PurchaseCode")publicvoidgivenTenCodesAndAMapWithCustomerCodeAndTargetTopicWhenTheStreamReceivesTenCodeThenEveryTargetTopicShouldReceiveItsPurchaseCode()throwsInterruptedException{// givenString[]purchaseCodes=Accounts.accounts;// purchase code format: salkdjaslkdajsdlajsdklajsdaklsjdfyhbeubyhquy12345kdalsdjaksldjasldjhvbfudybdudfubdf. ascii(0-15) + Customer_Code(15-20) + ascii(20+)// purchases code and topic map format: { "12345" : "TOPIC_CUSTOMER_1" , "54321" : "TOPIC_CUSTOMER_2" }// whenstream(purchaseCodes).forEach(this::sendMessage);// thenassertCodeIsInTopic(purchaseCodes[0],TOPIC_CUSTOMER1);assertCodeIsInTopic(purchaseCodes[1],TOPIC_CUSTOMER2);assertCodeIsInTopic(purchaseCodes[2],TOPIC_CUSTOMER3);assertCodeIsInTopic(purchaseCodes[3],TOPIC_CUSTOMER3);assertCodeIsInTopic(purchaseCodes[4],TOPIC_CUSTOMER4);assertCodeIsInTopic(purchaseCodes[5],TOPIC_CUSTOMER5);assertCodeIsInTopic(purchaseCodes[6],TOPIC_CUSTOMER1);assertCodeIsInTopic(purchaseCodes[7],TOPIC_CUSTOMER2);assertCodeIsInTopic(purchaseCodes[8],TOPIC_CUSTOMER1);assertCodeIsInTopic(purchaseCodes[9],TOPIC_CUSTOMER4);}privatevoidassertCodeIsInTopic(Stringcode,Stringtopic){OutputVerifier.compareKeyValue(readMessage(topic),null,code);}privatevoidsendMessage(finalStringmessage){finalKeyValue<String,String>kv=newKeyValue<String,String>(null,message);finalList<KeyValue<String,String>>keyValues=java.util.Arrays.asList(kv);finalList<ConsumerRecord<byte[],byte[]>>create=factory.create(keyValues);testDriver.pipeInput(create);}privateProducerRecord<String,String>readMessage(Stringtopic){returntestDriver.readOutput(topic,newStringDeserializer(),newStringDeserializer());}
Once we have our test finished we can verify that everything is fine
4. Integration tests
In the same way that the unit tests help us verify that our topology is well designed, the integration tests also help us in this task by adding the extra to introduce the kafka ecosystem in our tests.
This implies that our tests will be more “real” but in the other hand, they will be much slower.
Spring framework has developed a very useful library that provides all necessary to develop a good integration tests. Further information could be obtained here
Let’s suppose that we have the following scenario:
We have a topic with incoming transactions and we must group them by customer and create a balance of these transactions. This balance will have the sum of the transaction amounts, the transaction count, and the last timestamp.
Following the documentation, we have to define some configuration beans.
@Configuration@EnableKafkaStreamspublicclassKafkaStreamsConfiguration{@Value("${"+KafkaEmbedded.SPRING_EMBEDDED_KAFKA_BROKERS+"}")privateStringbrokerAddresses;@BeanpublicProducerFactory<String,Transaction>producerFactory(){returnnewDefaultKafkaProducerFactory<>(producerConfig());}@BeanpublicMap<String,Object>producerConfig(){Map<String,Object>senderProps=KafkaTestUtils.senderProps(this.brokerAddresses);senderProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class);senderProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,JsonSerializer.class);// producer ackssenderProps.put(ProducerConfig.ACKS_CONFIG,"all");// strongest producing guaranteesenderProps.put(ProducerConfig.RETRIES_CONFIG,"3");senderProps.put(ProducerConfig.LINGER_MS_CONFIG,"1");// leverage idempotent producer from Kafka 0.11 !//senderProps.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true"); // ensure we don't push duplicatessenderProps.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,"100");returnsenderProps;}@BeanpublicKafkaTemplate<String,Transaction>kafkaTemplate(){returnnewKafkaTemplate<>(producerFactory());}@Bean(name=KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)publicStreamsConfigkStreamsConfigs(){Map<String,Object>props=newHashMap<>();props.put(StreamsConfig.APPLICATION_ID_CONFIG,"testStreams-once-bank");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,this.brokerAddresses);props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG,Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,TransactionJsonSerde.class.getName());// Exactly once processing!!//props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE);props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,"100");returnnewStreamsConfig(props);}@BeanpublicTopologybankKStreamBuilder(BankBalanceKStreamBuilderstreamBuilder){returnstreamBuilder.build();}@BeanpublicBankBalanceKStreamBuilderbankstreamBuilder(StreamsBuilderstreamBuilder){returnnewBankBalanceKStreamBuilder(streamBuilder,BankBalanceKStreamBuilderTest.INPUT_TOPIC,BankBalanceKStreamBuilderTest.OUTPUT_TOPIC);}@BeanConsumer<String,String>consumerInput(){finalPropertiesprops=newProperties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,this.brokerAddresses);props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");props.put(ConsumerConfig.GROUP_ID_CONFIG,"KafkaExampleConsumerInput-transactions");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,"100");// Create the consumer using props.finalConsumer<String,String>consumer=newKafkaConsumer<>(props);// Subscribe to the topic.consumer.subscribe(Collections.singletonList(BankBalanceKStreamBuilderTest.INPUT_TOPIC));returnconsumer;}@BeanConsumer<String,String>consumerOutput(){finalPropertiesprops=newProperties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,this.brokerAddresses);props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");props.put(ConsumerConfig.GROUP_ID_CONFIG,"KafkaExampleConsumerOutput-balance");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,"100");// Create the consumer using props.finalConsumer<String,String>consumer=newKafkaConsumer<>(props);// Subscribe to the topic.consumer.subscribe(Collections.singletonList(BankBalanceKStreamBuilderTest.OUTPUT_TOPIC));returnconsumer;}}
Once we have our configuration class fine, we can create our integration tests.
@ExtendWith(SpringExtension.class)@ContextConfiguration(classes=KafkaStreamsConfiguration.class)@EmbeddedKafka(partitions=1,topics={BankBalanceKStreamBuilderTest.INPUT_TOPIC,BankBalanceKStreamBuilderTest.OUTPUT_TOPIC})publicclassBankBalanceKStreamBuilderTest{publicstaticfinalStringINPUT_TOPIC="input";publicstaticfinalStringOUTPUT_TOPIC="output";@AutowiredprivateKafkaTemplate<String,Transaction>template;@AutowiredConsumer<String,String>consumerInput;@AutowiredConsumer<String,String>consumerOutput;privatefinalExecutorexecutor=Executors.newCachedThreadPool();String[]names=newString[]{"David","John","Manuel","Carl"};@Test@DisplayName("Given A Large Number Of Transactions In Concurrent Mode When The Stream Process All Messages Then All Balances Should Be Calculated")publicvoidgivenALargeNumberOfTransactionsInConcurrentModeWhenTheStreamProcessAllMessagesThenAllBalancesShouldBeCalculated()throwsInterruptedException{intnumberOfTransactions=600;executor.execute(()->{for(inttransactionNumber=0;transactionNumber<numberOfTransactions;transactionNumber++){finalTransactiontransaction=newTransaction();transaction.setAmount(ThreadLocalRandom.current().nextDouble(0.0,100.0));finalStringname=names[ThreadLocalRandom.current().nextInt(0,4)];//we have only 4 mocked customers.transaction.setName(name);transaction.setTimestamp(System.nanoTime());template.send(INPUT_TOPIC,name,transaction);}});//we send the trasaction in a secondary thread.Awaitility.await().atMost(Duration.FIVE_MINUTES).pollInterval(newDuration(5,TimeUnit.SECONDS)).until(()->{intmessages=consumerInput.poll(1000).count();returnmessages==0;});// We assert al messages have been sent.assertEquals(4,consumerOutput.poll(1000).count());//As we have 4 different customers, we should have only four messages in the output topic.}}
Our tests is done, so we can verify everything is fine!
As we talked before, integration tests are very slower, and we can check this issue in the previous test. It takes 16 seconds on my machine, a huge amount of time.
5. Conclusion
If we want to develop a quality kafka streams we need to test the topologies and for that goal we can follow two approaches: kafka-tests and/or spring-kafka-tests.
In my humble opinion, we should develop both strategies in order to tests as cases as possible always maintaining a balance between both testing strategies.
In this Github Repo, there is available the tests for scenario 3.
The full source code for this article is available over on GitHub.
Last Monday, June 11, began the JBCNConf in Barcelona one of the biggest and important conference about the JVM in Spain.
I went as attendee and enjoyed the talks very much.
As I couldn’t go to all of them, I’ve been looking for the slides of all the talks so I can save them and read them with ease.
Below I will list all the ones I found:
Let’s suppose you have to implement a publisher with Redis and Spring Boot and you have to bringing down the instance when redis is unavailable.
The code could be something like that:
importorg.springframework.data.redis.RedisConnectionFailureException;importorg.springframework.data.redis.core.StringRedisTemplate;importorg.springframework.stereotype.Service;importlombok.extern.slf4j.Slf4j;@Service@Slf4jpublicclassMessagePublisherImplimplementsMessagePublisher{privatefinalStringRedisTemplateredisTemplate;publicMessagePublisherImpl(finalStringRedisTemplateredisTemplate){this.redisTemplate=redisTemplate;}@Overridepublicvoidpublish(finalStringmessage){try{redisTemplate.convertAndSend("myTopic",message);}catch(RedisConnectionFailureExceptione){log.error("Unable to connect to redis. Bringing down the instance");System.exit(1);}}}
This implementation is fine and It works as we expected but now, we have a problem…We want to test the code, specifically, we want to test booth branches in the publish method.
For that mision, first of all, I created two tests:
Given a message When is published Then is published by redis
@Test@DisplayName("Given a message When is published Then is published by redis")publicvoidgivenAMessageWhenIsPublishedThenIsPublishedByRedis(){// givenfinalStringmessage="Hi!";// whenmessagePublisher.publish(message);// thenverify(redisTemplate,times(1)).convertAndSend(anyString(),eq(message));}
Given the Redis instance down When a message is published Then the container is bringing down
@Test@DisplayName("Given the Redis instance down When a message is published Then the container is bringing down")publicvoidgivenTheRedisInstanceDownWhenAMessageIsPublishedThenTheContainerIsBringingDown(){// givenwillThrow(newRedisConnectionFailureException("")).given(redisTemplate).convertAndSend(anyString(),any());finalStringmessage="Hi!";// whenmessagePublisher.publish(message);// then// ???}
That’s right, It’s seems to be fine, now, when we executed the tests something weird occurrs.
Our tests execution are not ending due to the System.exit introduced in the publisher class.
How could I fix this issue?
Solution:
The most obvious answer is trying to mocking System.exit, so, let’s go.
As the javadoc shows us, System.exit method calls the exit method in class Runtime, thus, we should put the focus on that method.
We could create a Runtime Spy and exchange it with the static variable of the Runtine class and when the second test ends, we could leave everything as it was before.
Our test will be as following:
@Test@DisplayName("Given the Redis instance down When a message is published Then the container is bringing down")publicvoidgivenTheRedisInstanceDownWhenAMessageIsPublishedThenTheContainerIsBringingDown()throwsException{// givenwillThrow(newRedisConnectionFailureException("")).given(redisTemplate).convertAndSend(anyString(),any());finalStringmessage="Hi!";RuntimeoriginalRuntime=Runtime.getRuntime();RuntimespyRuntime=spy(originalRuntime);doNothing().when(spyRuntime).exit(eq(1));setField(Runtime.class,"currentRuntime",spyRuntime);// whenmessagePublisher.publish(message);// thenverify(spyRuntime,times(1)).exit(eq(1));setField(Runtime.class,"currentRuntime",originalRuntime);}privatevoidsetField(Class<?>clazz,Stringname,Objectspy)throwsException{finalFieldfield=clazz.getDeclaredField(name);field.setAccessible(true);field.set(null,spy);}
With this improve, our test suite runs fine and we have added an assert to the tests something important and that it did not have before.
Conclusions:
Thanks to Mockito and Java Reflection we can test almost all the cauisics that we find in our day to day.
The full source code for this article is available over on GitHub.
In that post, Slack engineers speaks about how they have redesigned their queue architecture and how they uses redis, consul and kafka.
It called my attention they used consul as a locking mechanism instead of redis because I have developed several locks with redis and it’s works great. Besides, they have integrated a redis cluster and I thnik this fact should facilitate its implementation.
After I read this post, I got doubts about which locking mechanism would have better performance so I develop both strategies of locking and a kafka queue to determine which gets the best performance.
My aim was to test the performance offered by sending thousands of messages to kafka and persisting them in mongo through a listener.
First of all, I built an environment with docker consisting of consul, redis, kafka, zookeeper and mongo. I wanted to test the performance of send thousands of messages to kafka and store it in mongo.
We can set up our environment with docker-compose.
docker-compose -up
Once we have our environment up, we need to create a kafka topic to channel the messages. For this we can rely on this tool, Kafka Tool.
At this point, our environment is fine, now, we have to implement a sender and a listener.
Sender:
I have created a simple spring boot web application with a rest controller that it help us to send as many messages as we want. This project has been created with the Spring Initializer Tool
This controller delegates in a sender the responsibility of comunicating with kafka:
importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.kafka.core.KafkaTemplate;importorg.springframework.kafka.support.SendResult;importorg.springframework.stereotype.Component;importorg.springframework.util.concurrent.ListenableFuture;importorg.springframework.util.concurrent.ListenableFutureCallback;importlombok.extern.slf4j.Slf4j;@Component@Slf4jpublicclassSender{@AutowiredprivateKafkaTemplate<String,String>kafkaTemplate;@AutowiredprivateListenableFutureCallback<?superSendResult<String,String>>callback;publicvoidsend(Stringtopic,Stringpayload){log.info("sending payload='{}' to topic='{}'",payload,topic);ListenableFuture<SendResult<String,String>>future=kafkaTemplate.send(topic,payload);future.addCallback(callback);}}
Now, we can send thousands of messages to kafka easily with a http request. In the following image we can see how send 5000 messages to kafka.
Finally, we just only have to implement the listener and the lock strategies.
Listener:
I have created other simple spring boot web which it is able to listen from kafka topics too.
In the first place, I researched about libraries that implemented locks mechanism in consul so that I only have to implement the lock strategy and I had not implement lock mechanism. I found consul-rest-client a rest client for consul that has everything I need.
As for redis, I have been working with Redisson with successful results both in performance and usability so I choose this library.
Config:
I’m going to divide the config’s section in three subsections: kafka, consul and redis.
From this configuration, we have to take notice in three configurations:
factory.setBatchListener(true);
I’m telling to kafka that I want to receive messages in batch mode, ergo instead of receive the messages one to one, we can receive hundreds of messages from a pull of the queue.
Later, we could see the different in performance.
Each different group id receives the same messages as we can see in the following diagram. With this separation, we are achieving a better horizontal scaling.
For the implementation of the consumer, I have used a kafka integration offered by spring.
In our consumer, I want to implement the following algorithm:
Iterate over the received messages
Deserialize json to dto object
Map dto object to domain entity.
Try to get lock
If this container has the lock
Build domain entity
Store the domain entity in the future persisted entities list.
Release lock
If I have been able to map to domain entity
Add to future persisted entities list
If the future persisted entities list is not empty
Persist the whole list
Send ack to kafka
Translated to java:
Consumer class:
importjava.io.IOException;importjava.util.ArrayList;importjava.util.Iterator;importjava.util.List;importjava.util.Optional;importjava.util.function.Function;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.kafka.annotation.KafkaListener;importorg.springframework.kafka.support.Acknowledgment;importorg.springframework.kafka.support.KafkaHeaders;importorg.springframework.messaging.handler.annotation.Header;importorg.springframework.messaging.handler.annotation.Payload;importorg.springframework.stereotype.Component;importorg.springframework.util.StringUtils;importcom.davromalc.kafka.model.Dto;importcom.davromalc.kafka.model.Event;importcom.davromalc.kafka.repositories.EventRepository;importconsul.ConsulException;importlombok.extern.slf4j.Slf4j;@Component@Slf4jpublicclassReceiver{privatefinalEventRepositoryeventRepository;privatefinalFunction<Dto,Optional<Event>>mapper;privatefinalObjectMapperobjectMapper=newObjectMapper();@AutowiredpublicReceiver(finalFunction<Dto,Optional<Event>>mapper,finalEventRepositoryeventRepository){this.mapper=mapper;this.eventRepository=eventRepository;}@KafkaListener(topics="myTopic",containerFactory="kafkaListenerContainerFactory",errorHandler="kafkaListenerErrorHandler")publicvoidreceive(@PayloadList<String>messages,@Header(KafkaHeaders.RECEIVED_PARTITION_ID)intpartition,@Header(KafkaHeaders.RECEIVED_TOPIC)List<String>topic,@Header("kafka_receivedTimestamp")longts,Acknowledgmentack)throwsConsulException,IOException{log.info("received from partition:[{}] [{}] elements with payload=[{}] , topic:[{}] , timestamp:[{}]",partition,messages.size(),StringUtils.collectionToCommaDelimitedString(messages),StringUtils.collectionToCommaDelimitedString(topic),ts);finalIterator<String>messagesIterator=messages.iterator();finalList<Event>eventsToPersist=newArrayList<>(messages.size());while(messagesIterator.hasNext()){finalDtodtoParsed=deserialize(messagesIterator.next());finalDtodto=Dto.builder().id(dtoParsed.getId()).timestamp(ts).partition(partition).data(dtoParsed.getData()).build();finalOptional<Event>event=mapper.apply(dto);if(event.isPresent()){eventsToPersist.add(event.get());}}if(!eventsToPersist.isEmpty()){log.info("Persisting [{}] objects",eventsToPersist.size());eventRepository.save(eventsToPersist);ack.acknowledge();}}}
Mapper class:
importjava.net.Inet4Address;importjava.net.UnknownHostException;importjava.time.Instant;importjava.time.LocalDateTime;importjava.time.ZoneId;importjava.util.Optional;importjava.util.function.Function;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.stereotype.Component;importcom.davromalc.kafka.model.Dto;importcom.davromalc.kafka.model.Event;importlombok.extern.slf4j.Slf4j;@Component@Slf4jpublicclassDtoToEventMapperimplementsFunction<Dto,Optional<Event>>{privatefinalLockHandler<?extendsFutureLock>lockHandler;privatefinalStringhostname;privatefinalZoneIdzoneId=ZoneId.systemDefault();@AutowiredpublicDtoToEventMapper(LockFactorylockFactory)throwsUnknownHostException{this.lockHandler=lockFactory.getLockHandler();this.hostname=Inet4Address.getLocalHost().getHostName();}@OverridepublicOptional<Event>apply(Dtodto){finalFutureLocklock=lockHandler.acquire(dto);booleanacquired=lock.tryLock();if(acquired){log.info("Adquired lock for id [{}] and host [{}]",dto.getId(),hostname);finalEventevent=newEvent();finalLocalDateTimedate=LocalDateTime.ofInstant(Instant.ofEpochMilli(dto.getTimestamp()),zoneId);event.setDate(date);event.setInsertDate(LocalDateTime.now());event.setPayload(dto.getData());event.setPartition(dto.getPartition());lockHandler.release(lock);returnOptional.of(event);}else{log.info("hostname [{}] did not adquire the lock for id [{}]",hostname,dto.getId());returnOptional.empty();}}}
To determine which blocking strategy to use, we use environment variables.
importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.core.env.Environment;importorg.springframework.stereotype.Component;@ComponentpublicclassLockFactory{privatestaticfinalStringREDIS="redis";privatestaticfinalStringCONSUL="consul";privatestaticfinalStringLOCK_TOOL="lockTool";privatefinalLockHandler<CustomRedisLock>redisLock;privatefinalLockHandler<CustomConsulLock>consulLock;privatefinalEnvironmentenv;@AutowiredpublicLockFactory(LockHandler<CustomRedisLock>redisLock,LockHandler<CustomConsulLock>consulLock,Environmentenv){this.redisLock=redisLock;this.consulLock=consulLock;this.env=env;}@SuppressWarnings("unchecked")public<TextendsFutureLock>LockHandler<T>getLockHandler(){if(env.getRequiredProperty(LOCK_TOOL).equalsIgnoreCase(CONSUL)){return(LockHandler<T>)consulLock;}elseif(env.getRequiredProperty(LOCK_TOOL).equalsIgnoreCase(REDIS)){return(LockHandler<T>)redisLock;}else{thrownewIllegalStateException("Unable to get Lock Tool");}}}
Stats:
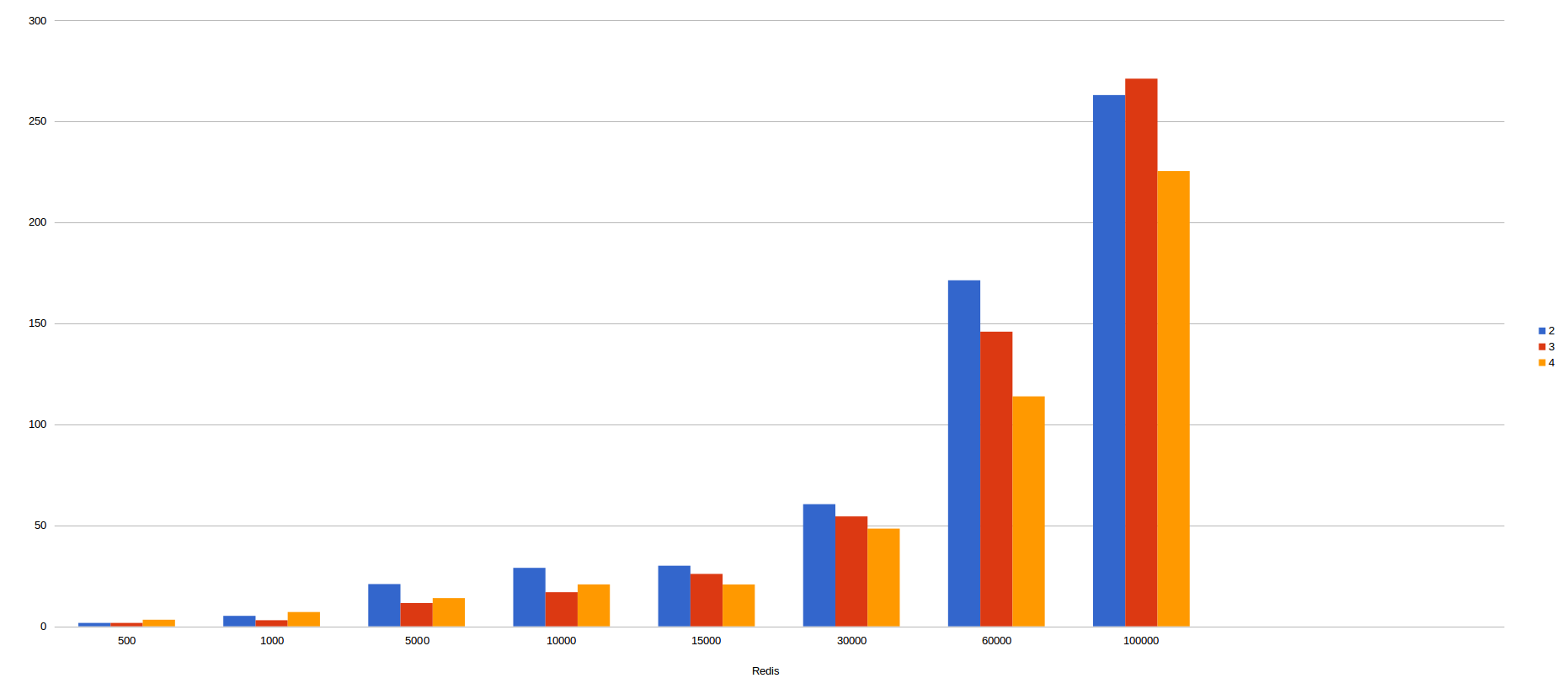
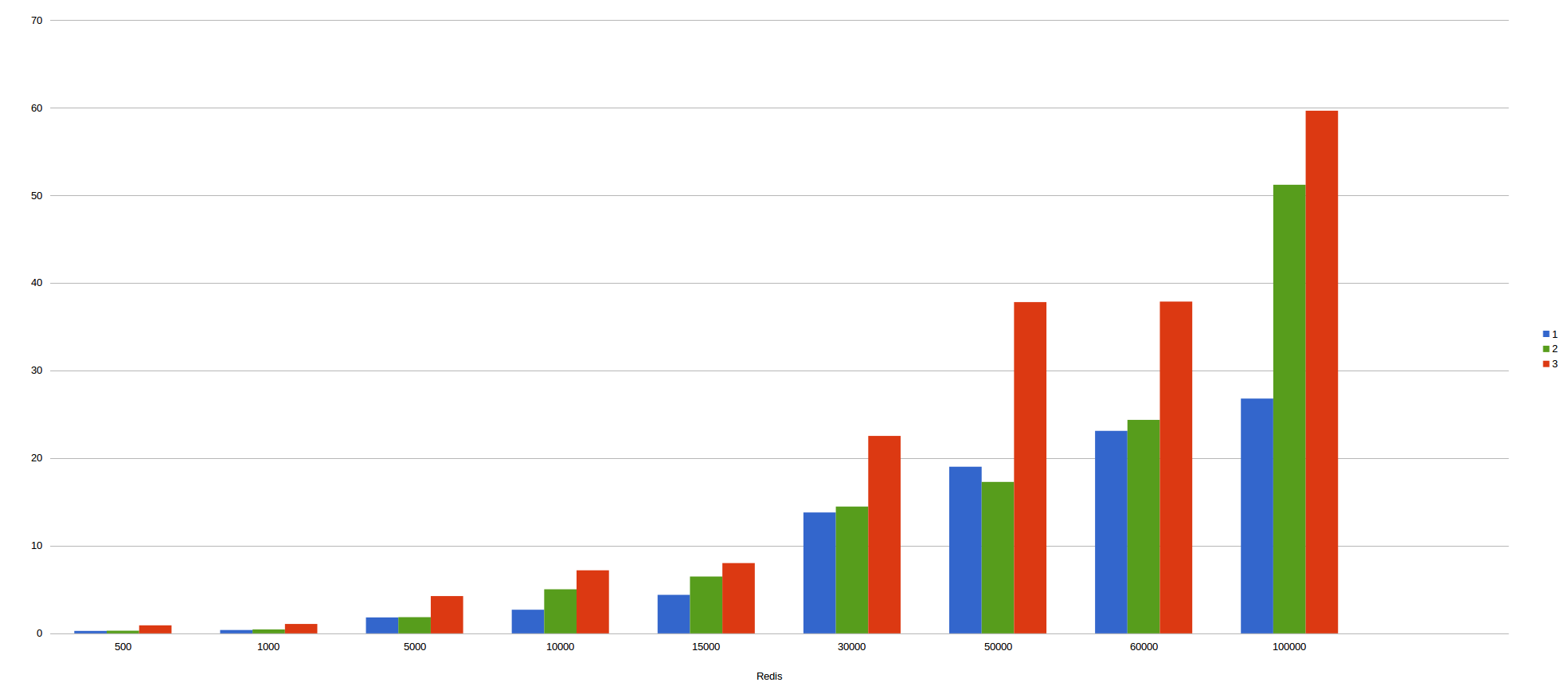
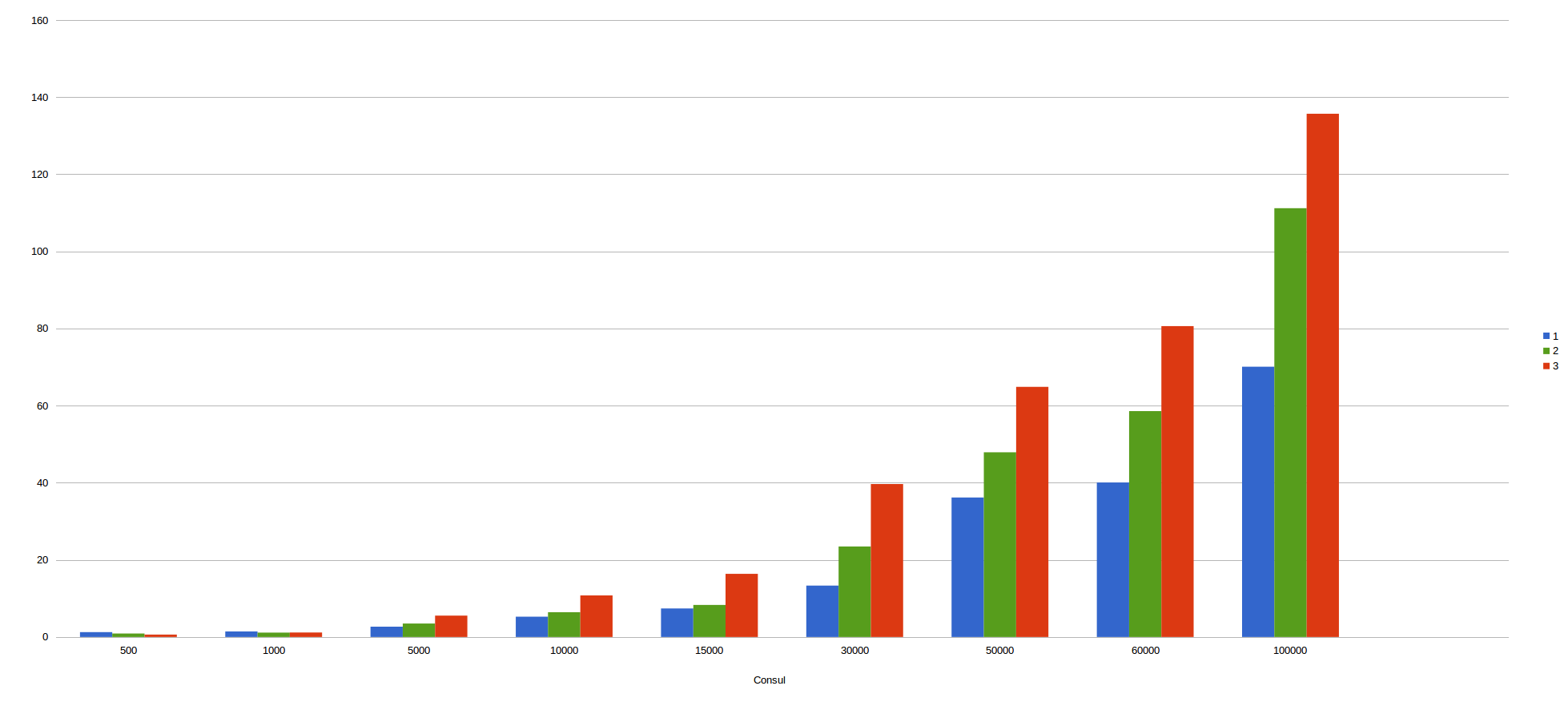
To determine the performance offered by both mechanism, I have been doing multiple benchmarcks with several executions, containers and number of messasges.
In the following pictures, we could see the results obtained by several executions in this scenarios visualized as diagrams:
Redis.
Redis with kafka batch mode.
Consul with kafka batch mode.
In the X axis, we can see the number of messages sent to kafka and in the Y axis we can see the total time spent in consuming all messages. The different colours represent the number of containers used in the benchmarcking.
Redis lock:
Redis lock with kafka batch mode:
Consul lock with kafka batch mode:
Conclusions:
In my humble opinion, we can infer kafka batch mode is faster than non batch mode since the different is incredibly big, reaching differences of more than 30 seconds as for example in 30.000 messages.
As for which is faster, we can also conclude that redis is faster than consul due to the results obtained. For example, 50.000 messages are consumed in redis in less than 20 seconds, meanwhile, Consul took about 40 seconds, double than redis. With 100.000 messages ocurrs the same. Redis wins with only 25 seconds approximately, nevertheless consul took more than 60 seconds, problematic times for real time applications.
As a curiosity, with kafka batch mode, the more container we use, the more time we took since when increasing the containers, we increase the requests to our infrastructure and therefore the latency and collisions.
However, as we persist a set of data instead of a single data, we substantially improve the times used thanks to mongo and its way of persisting large collections of data.
The full source code for this article is available over on GitHub.
Today, I have readed the Bonilista’s newsletter how every Sunday, for more than 18 months, and it made me think thant I should also make a list with my goals for the new year, and at the same time analyze how gone 2017 because I need to know how the year has gone to know if I’m on the right track or if I’ve lost my way.
Here we go with my 2017’s summary.
At the professional level it has been an excellent year because of my new position at Sngular. I joined to my new company in August and since them I have learned many technologies and techniques. In my new position I can enjoy my work and I have not suffered stress. The workload is managed with mastery which allows me to focus on doing quality work. In my last position I was happy too, but I needed new challengues.
Let’s review how the 2017 goals have been:
Work from home one day a week. Done! Since October, in my company we can work from home one or two day a week, nevertheless, I’m not working from home due the comfort and closeness I have right now. I think this goal is achieved above all because I have the possibility of working from home anytime.
Learn to disconnect from work. In Progress This goal is still in progress because of this problem I will always have. However, I have to improve my free time because the more relaxed I am, the better performance I will have.
Lead a healthier life. In Progress :warning: Being consistent, this goal will always be in my list because really I should always kept this goal in mind. I cannot be a great developer if I do not lead a healthier life.
Learn English seriously. In Progress The most important goal of 2017. In the first semester of the year, I forgot this goal but in the second semester I have been studying two days a week. At the beginning, I was studying only with two Apps (Duolingo and Babbel), but since December, I am studying with more resources like a native teacher, and cambridge’s resources. The next 27 of January, I will do the Cambrige examn. I want to obtain an english certificaiton. Some steps I have walked, such as writing all my posts in English. Blog
Attend conferences, talks and events related to the software. Fail I mark this goal as failure because of I have had near to achieve it. I followed some events online and watched by streaming. I mark this goal as failure because I could have been in the Codemotion but because of clumsiness I did not go.
On a personal level, the truth is that I have achieved few milestones, mainly for being very focused on my professional life.
I have not managed to obtain a certification in English, that is, I have to learn English seriously.
I have published only three posts in this Blog.
With the lesson learned from last year and what I want to be in 2018, these are my goals for new year.
Learn English seriously. This goal has to be the most important in 2018, I have to obtain an official certification and I have to learn English seriously. Without excuses, I must learn as much as possible. I think I have had a very good progress that I must strengthen and maintain in 2018.
Lead a healthier life. As I said before, this goal will always be on this list. Food and health should be a priority to avoid states of anxiety and to carry out a healthier life. I cannot forget this goal in 2018 and I must put many means into it.
Attend conferences, talks and events related to the software. Last year I followed from Twitter and Streaming, with much envy, many events related to the software community, like tarugoconf, codemotion, sevilla-jam, agile spain, etc … If I want to continue learning and growing in this community I must learn from better and it is clear that the best are in those events.
Get a certification I think to get a certification could be beneficial for my career. Maybe AWS cloud certification or Java Certification may help to me to improve my knowledge and my skills. And not only get a certification, I must also read the books I have pending (Clean Code, Clean Architecture, Java Effective Version 3) and all the books you consider relevant.
Honestly, I have to be realistic and focus on what is most important in order to achieve all the objectives.
In this article, we’ll se how to run a spring boot application with mongo db and a mongo client with a single command. For this purpose, we must dockerize our application, the mongo database and the mongo client.
Spring Boot Application
To create our Spring Boot application we use the project creation wizard provided by the Spring web.
Once the project is downloaded, we need to add the necessary configuration to dockerize the application and for the application to connect to Mongo.
How to dockerize the application
We only need to add a plugin to the pom.xml file and our application will aready been dockerized.
If we run mvn clean install we will see how our image has been created successfully.
mvn clean install
How to connect our app to mongo db
First of all, we need to add application.yml file. This file contains all configuration needed for our application
spring.data.mongodb:database:customers# Database name.uri:mongodb://mongo:27017# Mongo database URI. Cannot be set with host, port and credentials.
One of the first questions that would fit me would be:
Why does mongo appear as a host instead of localhost?
For one reason:
If we put localhost and run our application with docker, the mongo database won’t be founded. Mongo will be located in a container and our app will be located in a different container.
However, If we run our application with java, we only have to add following line to our /etc/hosts file.
mongo 127.0.0.1
Once the connection to mongo is configured, we need to add a repository to allow query database.
Additionally, we can add a controller that returns all the data, in json format, from mongo or to be able to persist new data.
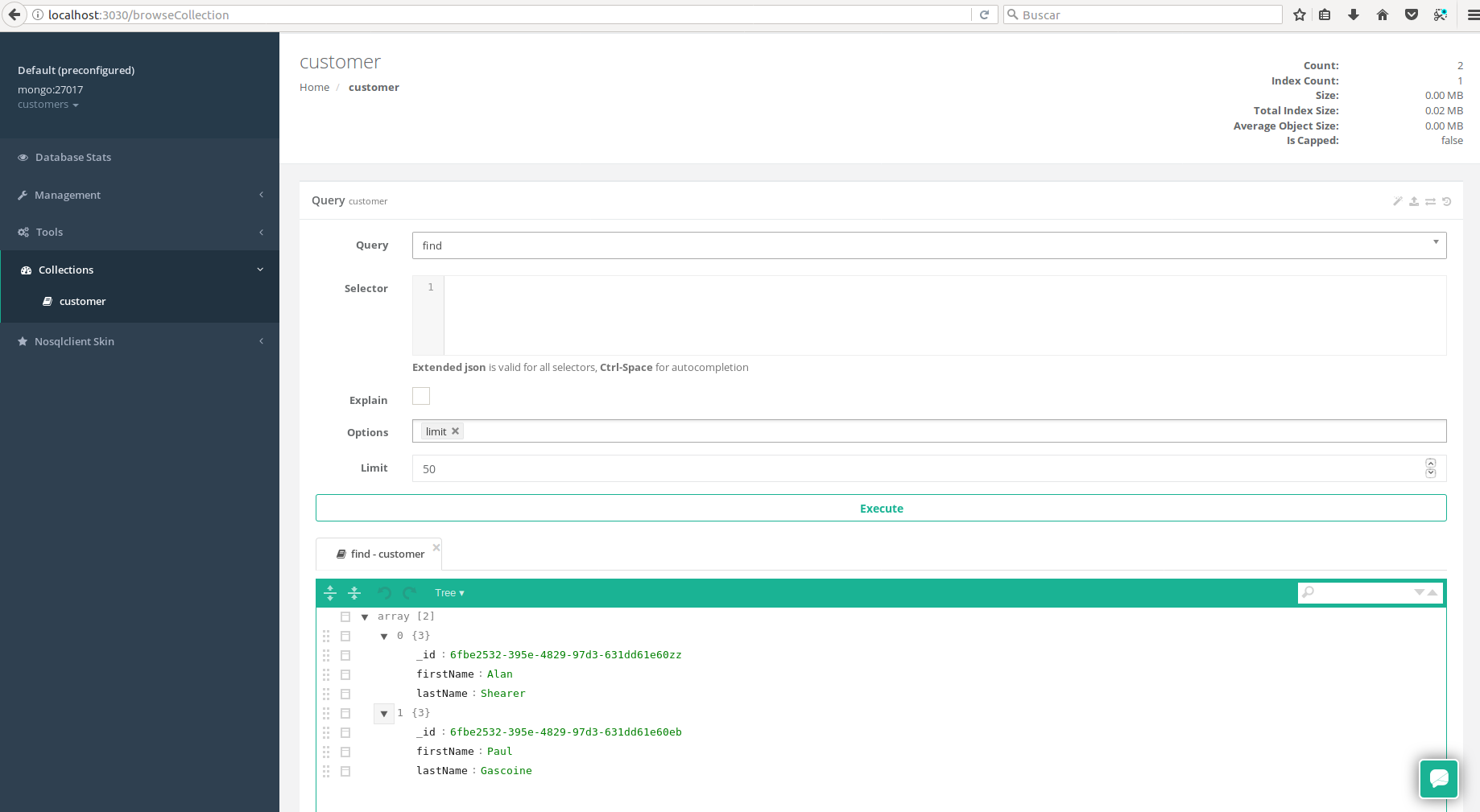
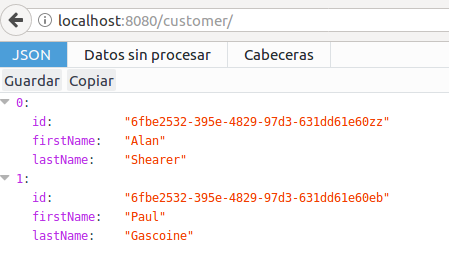
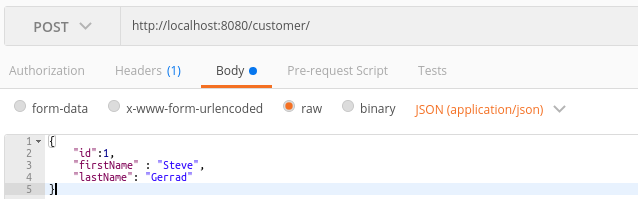
importjava.util.List;importorg.davromalc.tutorial.model.Customer;importorg.davromalc.tutorial.repository.CustomerRepository;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.web.bind.annotation.RequestBody;importorg.springframework.web.bind.annotation.RequestMapping;importorg.springframework.web.bind.annotation.RequestMethod;importorg.springframework.web.bind.annotation.RestController;importlombok.extern.slf4j.Slf4j;@RestController@Slf4jpublicclassCustomerRestController{@AutowiredprivateCustomerRepositoryrepository;@RequestMapping("customer/")publicListfindAll(){finalListcustomers=repository.findAll();log.info("Fetching customers from database {}",customers);returncustomers;}@RequestMapping(value="customer/",method=RequestMethod.POST)publicvoidsave(@RequestBodyCustomercustomer){log.info("Storing customer in database {}",customer);repository.save(customer);}}
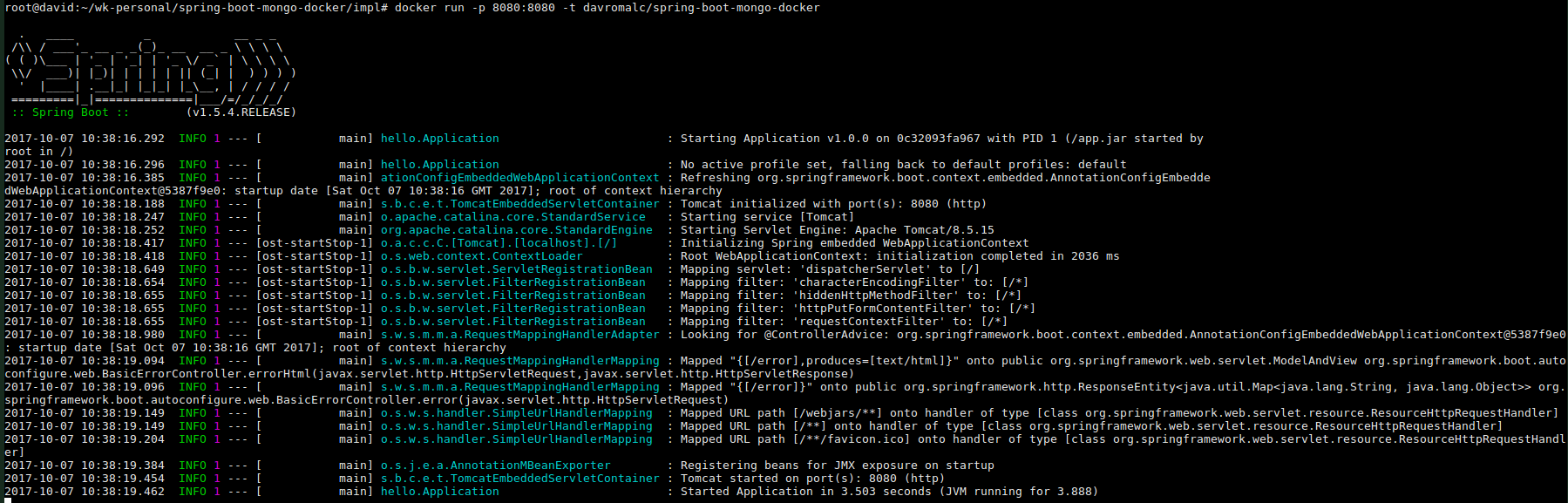
Our application is fine. We only have to create a docker image to be able to run a container with our application.
mvn clean install
Once the docker image is created, we can list all docker images and check if the docker image was created successfully.
Besides, we can run a container from the image created
At this point, we have our application dockerized but it cannot connect to mongo and we can’t see mongo data.
Mongo import
So that we can have data every time we start our mongo db, I have developed a script that persists in mongo the json files that we enter inside the folder mongo-init.
The script does the following:
For each folder inside the data-import folder, it reads all json files and creates a database with the name of the folder.
For each json file, it creates a collection with the name of the file and persists all json objects contained in the file.
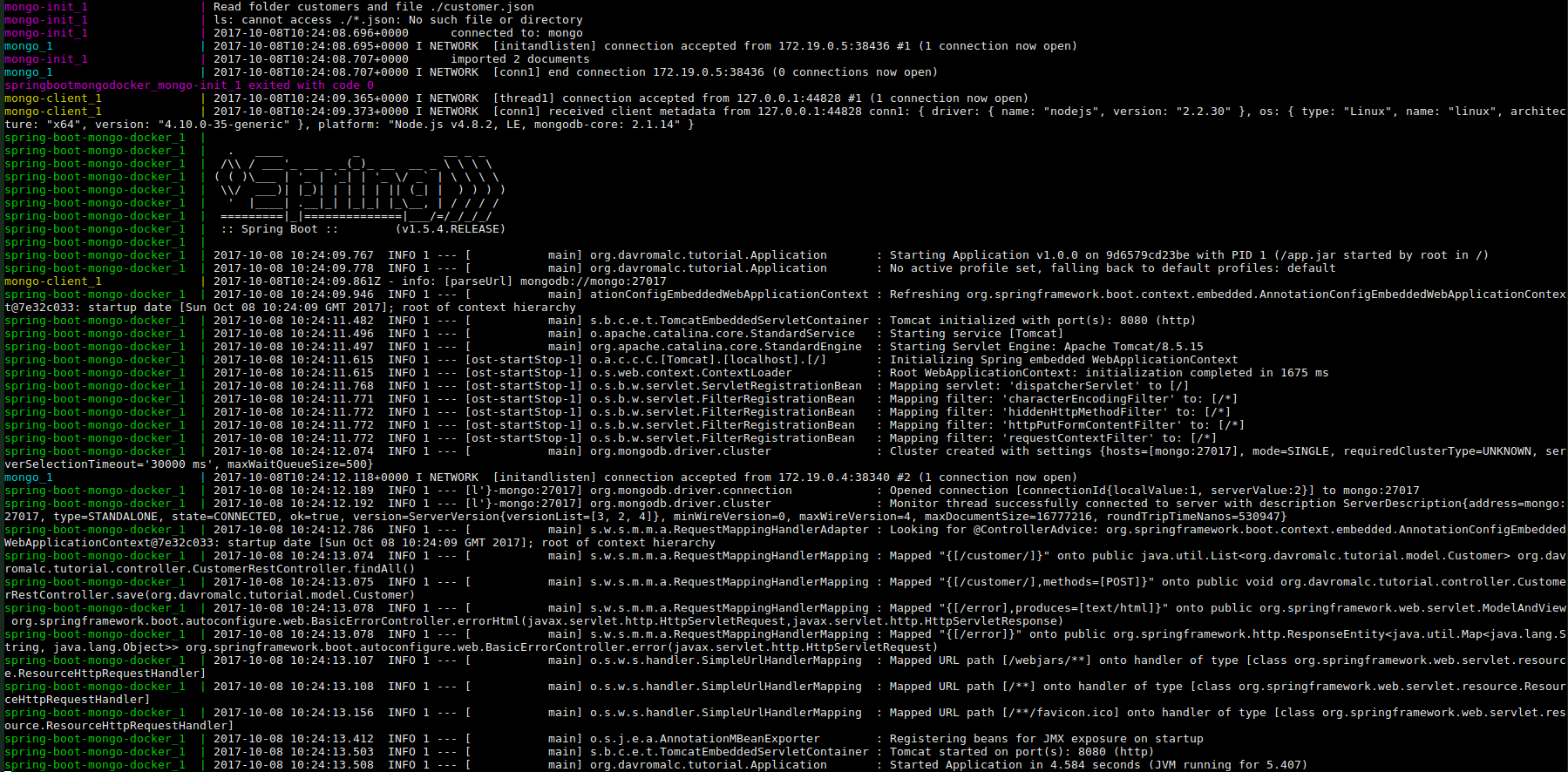
When we run this script, we can check if data is persited searching in logs.
Dockerized mongo
So that we do not have to have installed mongo in our laptop, we can dockerize mongo and only use it when it is necessary and to be able to export all our technology stack easily.
We only have to search docker image and pull from the repository.
docker pull mongo:latest
Mongo client
Mongo Client is a web interface that allows us to visualize in a simple way the contents of our collections.
We only have to search docker image and pull from the repository.
We do not need to pull the image, when we run the docker compose this will download all the images that are not founded in our local repository.
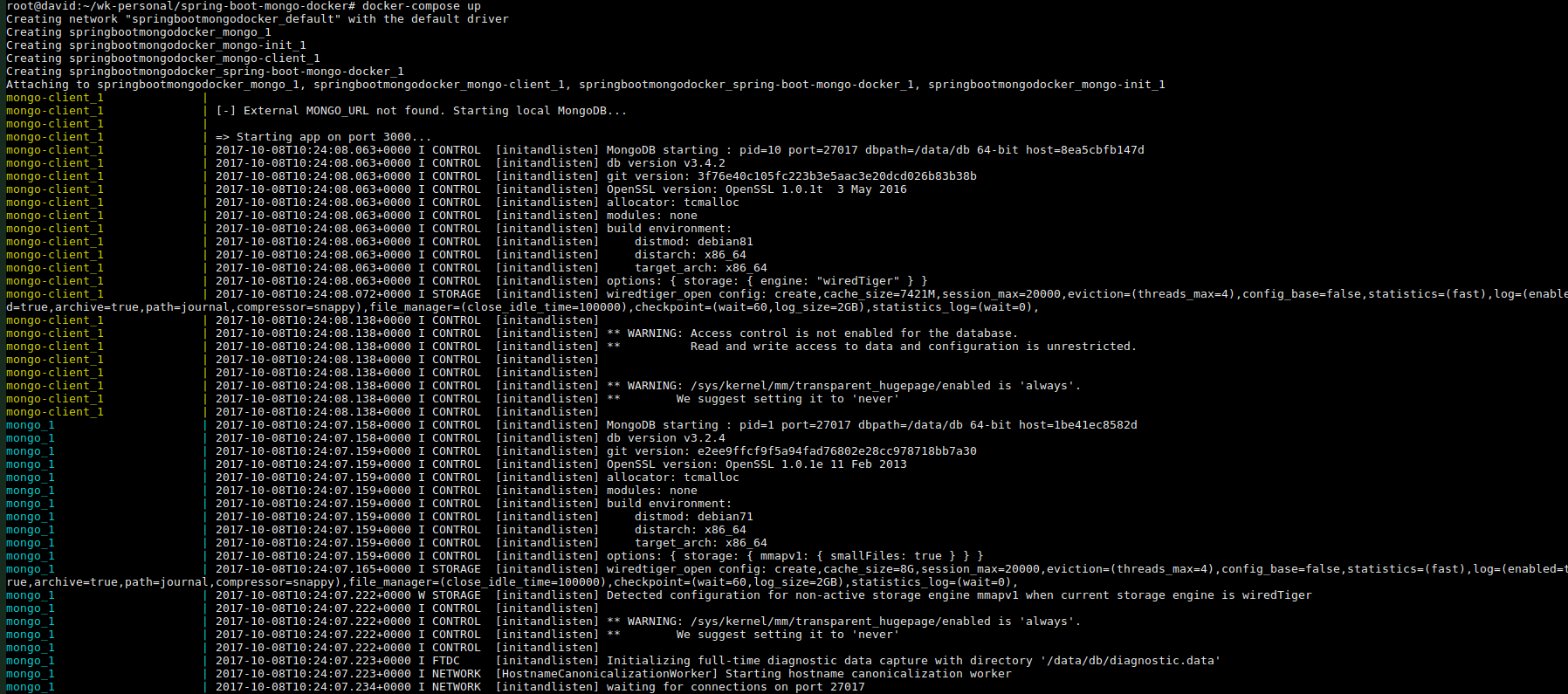
Run all with a single command.
If we wanted to run our application, with mongodb, with the imported data and with mongo client we would need to execute the 4 containers in the following order:
Mongo
Mongo Import
Mongo Client
App
Running 4 commands every time we make a change is not very useful and often causes bugs.
To solve this problem, we have the docker compose tool that allows us to execute several containers of the same stack and create links between the different containers so that they have visibility between them.
We are going to inspect the contents of this file:
Services means each container we will run
Mongo: We are going to use mongo image and expose its tipically port: 27017
Mongo Init: Build from Dockerfile . Copy the script into the container and run it. It have a link with mongo container. This link is very importante so if this link does not exist, the data would not persist in the desired mongo.
Mongo Client: From latest docker i :Dmage. The url of the mongo to which it accedes must be configured through environment. As in the application.yml file we must indicate the url with “mongo” and not with “localhost”. And why mongo? Because mongo is the name of the mongo service declared in line 3. If in line 3 we would have declared the service as my-mongo-database, in this environment variable we should put: mongodb://my-mongo-database:27017 and the same in the application.yml file.
App: From the image created above. We expose 8080 port. We set a link with mongo. If we doesn’t set this link, our app would nott run.
At this point, we can run the 4 containers with a single command, as we promised at the beginning of this article. 😀
We should to run the following command:
docker-compose -up
Each container has been executed successfully and we can’t see errors in logs.
Note: If we modify the dataset of mongo init, we hace yo re-build the docker-image. For that purpouse, we hace to run the following command:
docker-compose up --build
Now, We can check if all configuration is fine and if we can access mongo data from mongo client and from our application.
Mongo Client:
Our Application:
Logs Ouput:
Create customer with postman tool
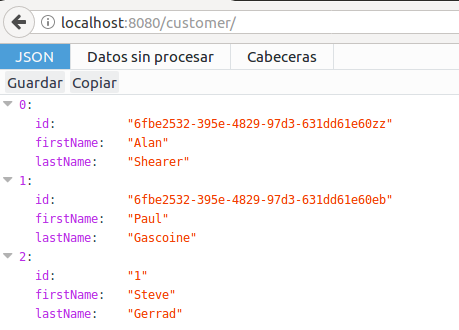
Now, we can check if customer has been persisted successfully.
Conclusion
Thanks to the docker-compose tool we can build a poweful technological stack that helps us develop and build spring boot applications in a simple and intuitive way.
Mongo client and mongo import data are two useful tools for development that allow us to speed up the development of our application and have an clean dataset every time we run the application. This is very helpful to run the integration tests for example.
The full source code for this article is available over on GitHub.
Since the beginning of 2017, I have been instilling in my company the importance and necessity of having a strong CI environment. I started installing Jenkins in a small server and right now I’ve got a project to implement continuous integration for all the development teams in the company.
In this post I would like to share many of the acquired knowledge.
Workflow definition
First of all, we have designed a workflow for all projects. If each project pass the workflow we can achieve a good quality in the software factory.
Besides, we can automatize every deploy done to each environment.
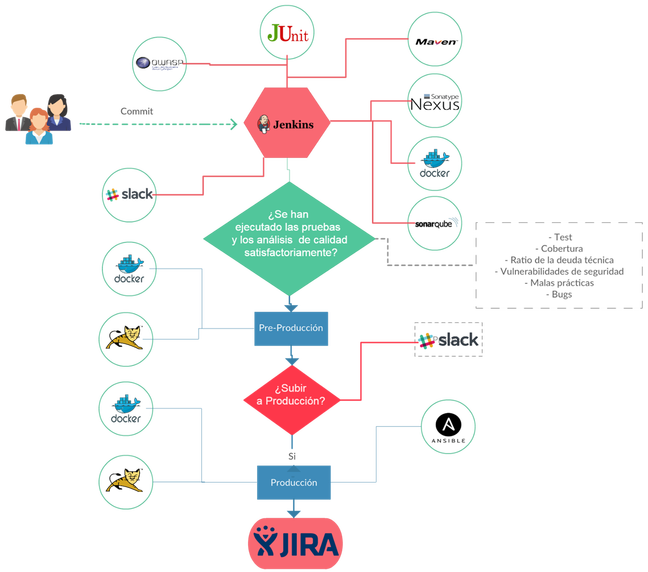
Attached a diagram with the proposal workflow.
The workflow contains the following stages:
Checkout the code
Compile the code
Execute tests
Quality code analisys, check coverage and OWASP analysis.
Deploy to pre-production environment
User confirmation
Tag the code
Deploy to production environment
Publish to Slack and Jira
Workflow implementation
I think the version 2 of Jenkins is the most appropiate tool for this job, since they have incorporated a new feature to create “pipelines” with code. These pipelines are groovy scripts.
So I got down to work and started working with Jenkins Pipeline not without giving me the some headache.
I chose Maven as the main tool since with different plugins it allows me to carry out most of the actions of the workflow. I could also have used the Jenkins plugins but they are not updated to support the pipeline.
Attached code:
#!groovypipeline{agentany//Docker agent. In the future, we will work with dockertools{//Jenkins installed toolsmaven'M3'//Maven tool defined in jenkins configurationjdk'JDK8'//Java tool defined in jenkin configuration}options{//If after 3 days the pipeline does not finish, please aborttimeout(time:76,unit:'HOURS')}environment{//Project nameAPP_NAME='My-App'}stages{//Stages definitionstage('Initialize'){//Send message to slack at the beginningsteps{slackSend(message:'Start pipeline '+APP_NAME,channel:'#jenkins',color:'#0000FF',teamDomain:'my-company',token:'XXXXXXXXXXXXXXXXXXX')}}stage('Build'){//Compile stagesteps{bat"mvn -T 4 -B --batch-mode -V -U -e -Dmaven.test.failure.ignore clean package -Dmaven.test.skip=true"}}stage('Test'){//Tests stage. We use parrallel mode.steps{parallel'Integration & Unit Tests':{bat"mvn -T 4 -B --batch-mode -V -U -e test"},'Performance Test':{bat"mvn jmeter:jmeter"}}}stage('QA'){//QA stage. Parallel mode with Sonar, Coverage and OWASPsteps{parallel'Sonarqube Analysis':{bat"mvn -B --batch-mode -V -U -e org.jacoco:jacoco-maven-plugin:prepare-agent install -Dmaven.test.failure.ignore=true"bat"mvn -B --batch-mode -V -U -e sonar:sonar"},'Check code coverage':{//Check coverage//If coverage is under 80% the pipeline fails.bat"mvn -B --batch-mode -V -U -e verify"},'OWASP Analysis':{bat"mvn -B -X --batch-mode -V -U -e dependency-check:check"}}//We store tests reports.post{success{junit'target/surefire-reports/**/*.xml'}}}stage('Deploy to Pre-production environment'){//We use maven cargo plugin to deploy in tomcat.steps{bat"mvn -B -P Desarrollo --batch-mode -V -U -e clean package cargo:redeploy -Dmaven.test.skip=true"}}stage('Confirmation'){//In this stage, pipeline wait until user confirm next stage.//It sends slack messagessteps{slackSendchannel:'@boss',color:'#00FF00',message:'\u00BFDo you want to deploy to production environment?. \n Link: ${BLUE_OCEAN_URL}',teamDomain:'my-company',token:'XXXXXXXXXXX'timeout(time:72,unit:'HOURS'){input'Should the project '+APP_NAME+' be deployed to production environment\u003F'}}}stage('Tagging the release candidate'){steps{//Tagging from trunk to tagecho"Tagging the release Candidate";bat"mvn -B --batch-mode -V -U -e scm:tag -Dmaven.test.skip=true"}}stage('Deploy to Production environment'){//We deploy in parrallel mode during 6 times. steps{parallel'Server 1':{retry(6){bat"mvn -T 4 -B -P Produccion --batch-mode -V -U -e tomcat7:redeploy -Dmaven.test.skip=true"}},'Server 2':{retry(6){bat"mvn -T 4 -B -P Produccion --batch-mode -V -U -e tomcat:redeploy -Dmaven.test.skip=true"}}}}stage('CleanUp'){//The pipeline remove all temporal files.steps{deleteDir()}}}//End of stages//Post-workflow actions.//The pipeline sends messages with the result of the executionpost{success{slackSendchannel:'#jenkins',color:'#00FF00',message:APP_NAME+' executed successfully.',teamDomain:'my-company',token:'XXXXXXXXXXXXXXXXXXXX'}failure{slackSendchannel:'#jenkins',color:'#FF0000',message:APP_NAME+' is failure!!!. ${BLUE_OCEAN_URL}',teamDomain:'my-company',token:'XXXXXXXXXXXXXXXX'}unstable{slackSendchannel:'#jenkins',color:'#FFFF00',message:APP_NAME+' is unstable!!!. ${BLUE_OCEAN_URL}',teamDomain:'my-company',token:'XXXXXXXXXXXXXXXXXXXX'}}}
With Jenkins we can automate a lot of task that developer would have to do instead of develop code, in addition those task are prone to failures, with which we remove that possibility. We can also impose a series of quality rules in the code that have to be fulfilled if we want to deploy a new version.
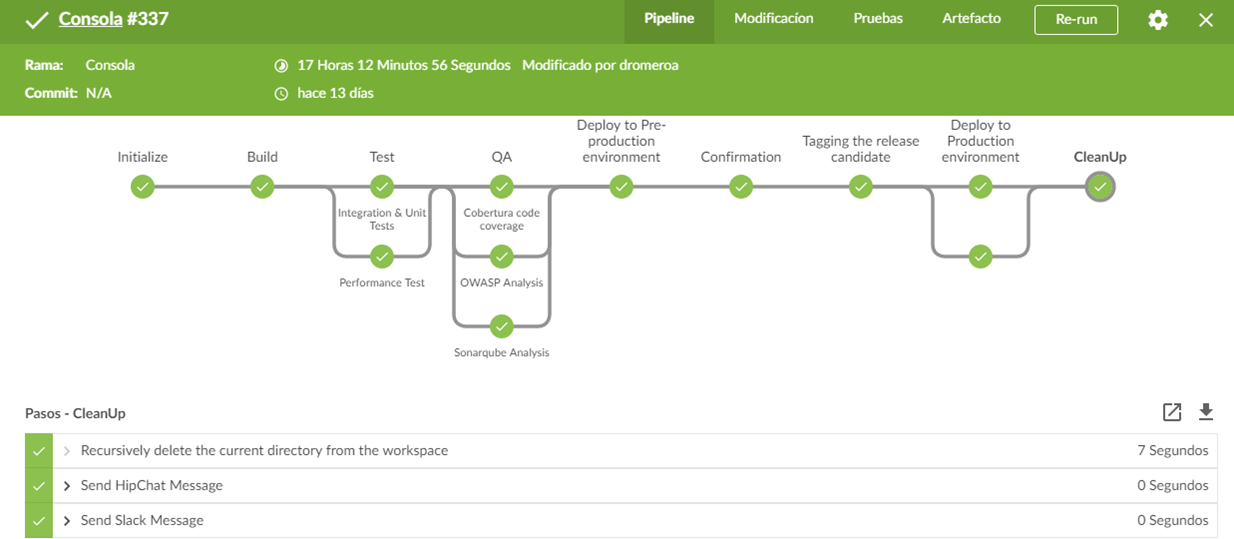
Below is shown a real execution of the pipeline in Jenkin. Our Jenkins has installed the Blue Ocen Plugin. This plugins improve the Jenkins UI.
Next Steps:
Docker integration. Execute stages in docker containers.
Ansible integration. Deploy to multiple servers with one command.
Jira Api Rest. Publish in Jira the release notes.
If you have any doubt, please contact me or leave a comment and so I can help anybody interested in Jenkins pipeline :)
Yesterday, first of January, I read the Bonilista’s newsletter ] how every Sunday, for more than 6 months, and it made me think thant I should also make a list with my goals for the new year, and at the same time analyze how gone 2016 because I need to know how the year has gone to know if I’m on the right track or if I’ve lost my way.
Here we go with my summary of 2016
At the professional level it has been a very good year due to my great progression in my company. I have learned a lot, I have programmed everything I have wanted and more, I have introduced new technologies in the company, I have introduced new concepts needed in a software factory and most importantly I have been happy. On the contrary, I have suffered a lot of stress due to high workload and not knowing how to disconnect from work.
On a personal level, the truth is that I have no achieved milestones, mainly for being very focused on my professional life.
I have not managed to obtain a certification in English, that is, I have to learn English seriously.
I have not managed to lead a healthier life.
I forgot a bit my family and couple.
I have not published anything in this Blog.
In relation to my needs, these are my goals for 2017.
Work from home one day a week. This objective I think is important because I like to work with my timing, with my schedule and 100% focused on work, therefore, I am happy. I think it can be achieved because the company is facilitating this possibility and therefore it is something that I should take advantage of.
Learn to disconnect from work. A great burden that haunts me since I started working. If there is not something I can do, that helps me lose time, that helps me read and write, that I like it more, that it does not disconnect me more irascible
Lead a healthier life. Due to the high level of stress suffered in 2016, food and health has not been a priority for me in the wake of states of anxiety and to carry out a feeding sometimes harmful. This can not happen in 2017 and I must put many means into it.
Learn English seriously. Nowadays I can not afford the luxury of not speak English at a high level. There are no excuses and we must remedy it. No more If I achieve this goal I will get an official certification, so get to work.
Attend conferences, talks and events related to the software. Last year I followed from Twitter, with much envy, many events related to the software community, like tarugoconf, codemotion, sevilla-jam, agile spain, etc … If I want to continue learning and growing in this community I must learn from better and it is clear that the best are in those events.
Honestly, they come to my head 5 or 6 more goals but I think I have to be realistic and focus on what is most important in order to achieve all the objectives.