
A month or so ago, I read a post in Slack Engineering’s blog about how Slack handles billions of tasks in miliseconds.
In that post, Slack engineers speaks about how they have redesigned their queue architecture and how they uses redis, consul and kafka.
It called my attention they used consul as a locking mechanism instead of redis because I have developed several locks with redis and it’s works great. Besides, they have integrated a redis cluster and I thnik this fact should facilitate its implementation.
After I read this post, I got doubts about which locking mechanism would have better performance so I develop both strategies of locking and a kafka queue to determine which gets the best performance.
My aim was to test the performance offered by sending thousands of messages to kafka and persisting them in mongo through a listener.
First of all, I built an environment with docker consisting of consul, redis, kafka, zookeeper and mongo. I wanted to test the performance of send thousands of messages to kafka and store it in mongo.
Set up environment:
version: "3"
services:
consul:
image: consul:latest
command: agent -server -dev -client 0.0.0.0 -log-level err
ports:
- 8500:8500
healthcheck:
test: "exit 0"
redis:
image: redis
ports:
- "6379:6379"
mongo:
image: mongo:3.2.4
ports:
- 27017:27017
command: --smallfiles
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
hostname:
"kafka"
environment:
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_PORT: 9092
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false'We can set up our environment with docker-compose.
docker-compose -up
Once we have our environment up, we need to create a kafka topic to channel the messages. For this we can rely on this tool, Kafka Tool.
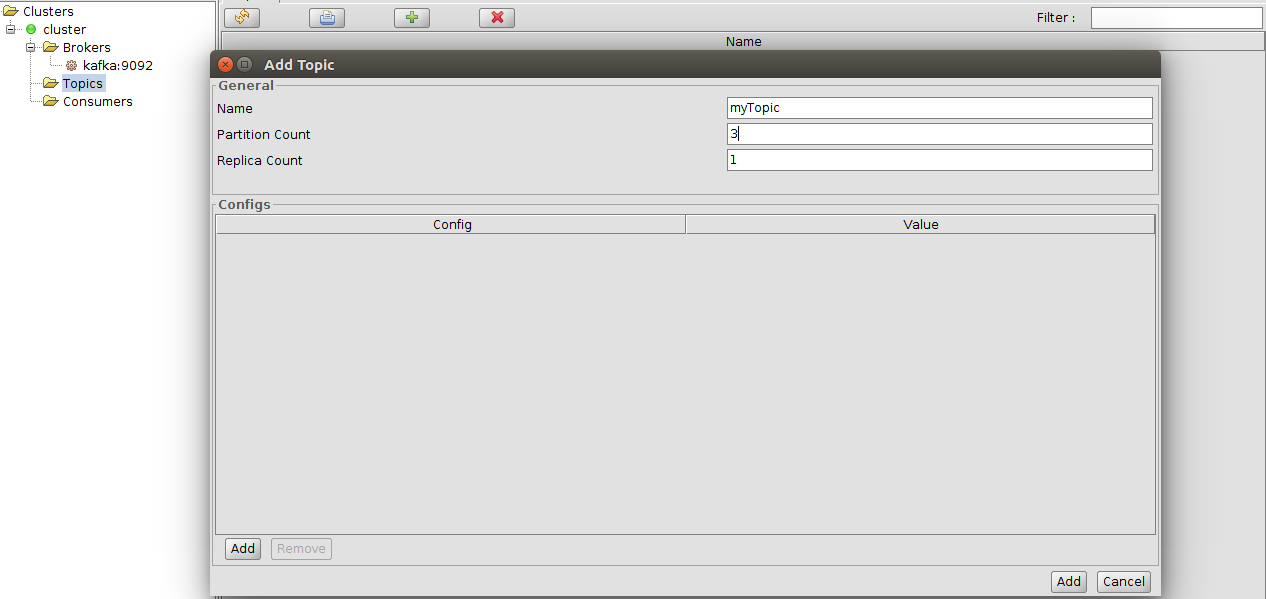

At this point, our environment is fine, now, we have to implement a sender and a listener.
Sender:
I have created a simple spring boot web application with a rest controller that it help us to send as many messages as we want. This project has been created with the Spring Initializer Tool
Config:
We only have to set up the kafka configuration:
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
@EnableKafka
@Configuration
public class KafkaConfig {
@Value(value = "${kafka.bootstrapAddress}")
private String bootstrapAddress;
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}And this is the rest controller in charge of sending the messages to kafka:
@PostMapping("/api/send/{messages}/")
public ResponseEntity<String> send(@PathVariable int messages,@RequestBody String message){
IntStream.range(0, messages).parallel().boxed()
.map(i -> new Dto(i, message.concat(RandomStringUtils.randomAlphanumeric(80))))
.map(this::serialize)
.forEach(s -> sender.send(TOPIC, s));
return ResponseEntity.ok("OK");
}This controller delegates in a sender the responsibility of comunicating with kafka:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import lombok.extern.slf4j.Slf4j;
@Component
@Slf4j
public class Sender {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
private ListenableFutureCallback<? super SendResult<String, String>> callback;
public void send(String topic, String payload) {
log.info("sending payload='{}' to topic='{}'", payload, topic);
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, payload);
future.addCallback(callback);
}
}Now, we can send thousands of messages to kafka easily with a http request. In the following image we can see how send 5000 messages to kafka.

Finally, we just only have to implement the listener and the lock strategies.
Listener:
I have created other simple spring boot web which it is able to listen from kafka topics too.
In the first place, I researched about libraries that implemented locks mechanism in consul so that I only have to implement the lock strategy and I had not implement lock mechanism. I found consul-rest-client a rest client for consul that has everything I need.
As for redis, I have been working with Redisson with successful results both in performance and usability so I choose this library.
Config:
I’m going to divide the config’s section in three subsections: kafka, consul and redis.
Kafka:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.Environment;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.AbstractMessageListenerContainer.AckMode;
@EnableKafka
@Configuration
public class KafkaConfig {
@Value(value = "${kafka.bootstrapAddress}")
private String bootstrapAddress;
@Value(value = "${kafka.groupId.key}")
private String groupIdKey;
@Value(value = "${kafka.groupId.defaultValue}")
private String groupIdDefaultValue;
@Autowired
private Environment env;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
props.put(ConsumerConfig.GROUP_ID_CONFIG, env.getProperty(groupIdKey, groupIdDefaultValue));
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
@Bean
ConcurrentKafkaListenerContainerFactory<Integer, String>
kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(5);
factory.setBatchListener(true);
factory.getContainerProperties().setAckMode(AckMode.MANUAL_IMMEDIATE);
factory.getContainerProperties().setPollTimeout(5000);
return factory;
}
@Bean
public ConsumerFactory<Integer, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}From this configuration, we have to take notice in three configurations:
- factory.setBatchListener(true);
I’m telling to kafka that I want to receive messages in batch mode, ergo instead of receive the messages one to one, we can receive hundreds of messages from a pull of the queue. Later, we could see the different in performance.
- factory.getContainerProperties().setAckMode(AckMode.MANUAL_IMMEDIATE);
I’m telling to kafka that I want to do manual ack because until a message is not persisted to mongo I can not assure that the message is read.
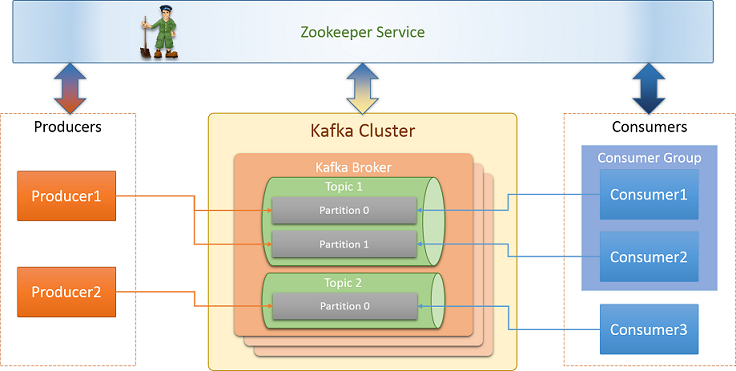
- props.put(ConsumerConfig.GROUP_ID_CONFIG, env.getProperty(groupIdKey, groupIdDefaultValue));
Each different group id receives the same messages as we can see in the following diagram. With this separation, we are achieving a better horizontal scaling.
Consul:
import java.net.Inet4Address;
import java.net.UnknownHostException;
import java.util.Random;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import consul.Consul;
import consul.ConsulException;
@Configuration
public class ConsulConfig {
private final String hostname;
private final Random random = new Random();
@Value(value = "${consul.server}")
private String consulHost;
@Value(value = "${consul.port}")
private int consulPort;
public ConsulConfig() throws UnknownHostException {
this.hostname = Inet4Address.getLocalHost().getHostName() + random.nextInt(80000);
}
@Bean
public Consul consul() {
return new Consul("http://"+consulHost, consulPort);
}
@Bean
public String sessionId(final Consul consul) throws ConsulException {
return consul.session().create(hostname);
}
}Consul handles the locking mechanism by sessionId, so, we have to create different sessionId in each new service.
Redis:
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RedisConfig {
@Value(value = "${redis.server}")
private String redisHost;
@Value(value = "${redis.port}")
private int redisPort;
@Bean
public RedissonClient redisson() {
Config config = new Config();
config.useSingleServer().setAddress("redis://" + redisHost + ":" + redisPort);
return Redisson.create(config);
}
}Redis config is very easy.
Consumer:
For the implementation of the consumer, I have used a kafka integration offered by spring.
In our consumer, I want to implement the following algorithm:
- Iterate over the received messages
- Deserialize json to dto object
- Map dto object to domain entity.
- Try to get lock
- If this container has the lock
- Build domain entity
- Store the domain entity in the future persisted entities list.
- Release lock
- If I have been able to map to domain entity
- Add to future persisted entities list
- If the future persisted entities list is not empty
- Persist the whole list
- Send ack to kafka
Translated to java:
Consumer class:
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Optional;
import java.util.function.Function;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import com.davromalc.kafka.model.Dto;
import com.davromalc.kafka.model.Event;
import com.davromalc.kafka.repositories.EventRepository;
import consul.ConsulException;
import lombok.extern.slf4j.Slf4j;
@Component
@Slf4j
public class Receiver {
private final EventRepository eventRepository;
private final Function<Dto, Optional<Event>> mapper;
private final ObjectMapper objectMapper = new ObjectMapper();
@Autowired
public Receiver(final Function<Dto, Optional<Event>> mapper,final EventRepository eventRepository) {
this.mapper = mapper;
this.eventRepository = eventRepository;
}
@KafkaListener(topics = "myTopic", containerFactory = "kafkaListenerContainerFactory", errorHandler = "kafkaListenerErrorHandler")
public void receive(@Payload List<String> messages, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) List<String> topic, @Header("kafka_receivedTimestamp") long ts,
Acknowledgment ack) throws ConsulException, IOException {
log.info("received from partition:[{}] [{}] elements with payload=[{}] , topic:[{}] , timestamp:[{}]",
partition, messages.size(), StringUtils.collectionToCommaDelimitedString(messages),
StringUtils.collectionToCommaDelimitedString(topic), ts);
final Iterator<String> messagesIterator = messages.iterator();
final List<Event> eventsToPersist = new ArrayList<>(messages.size());
while ( messagesIterator.hasNext() ){
final Dto dtoParsed = deserialize(messagesIterator.next());
final Dto dto = Dto.builder().id(dtoParsed.getId()).timestamp(ts).partition(partition).data(dtoParsed.getData()).build();
final Optional<Event> event = mapper.apply(dto);
if (event.isPresent()){
eventsToPersist.add(event.get());
}
}
if (!eventsToPersist.isEmpty()) {
log.info("Persisting [{}] objects", eventsToPersist.size());
eventRepository.save(eventsToPersist);
ack.acknowledge();
}
}
}Mapper class:
import java.net.Inet4Address;
import java.net.UnknownHostException;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.util.Optional;
import java.util.function.Function;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import com.davromalc.kafka.model.Dto;
import com.davromalc.kafka.model.Event;
import lombok.extern.slf4j.Slf4j;
@Component
@Slf4j
public class DtoToEventMapper implements Function<Dto, Optional<Event>> {
private final LockHandler<? extends FutureLock> lockHandler;
private final String hostname;
private final ZoneId zoneId = ZoneId.systemDefault();
@Autowired
public DtoToEventMapper(LockFactory lockFactory) throws UnknownHostException {
this.lockHandler = lockFactory.getLockHandler();
this.hostname = Inet4Address.getLocalHost().getHostName();
}
@Override
public Optional<Event> apply(Dto dto) {
final FutureLock lock = lockHandler.acquire(dto);
boolean acquired = lock.tryLock();
if (acquired) {
log.info("Adquired lock for id [{}] and host [{}]", dto.getId(), hostname);
final Event event = new Event();
final LocalDateTime date = LocalDateTime.ofInstant(Instant.ofEpochMilli(dto.getTimestamp()), zoneId);
event.setDate(date);
event.setInsertDate(LocalDateTime.now());
event.setPayload(dto.getData());
event.setPartition(dto.getPartition());
lockHandler.release(lock);
return Optional.of(event);
} else {
log.info("hostname [{}] did not adquire the lock for id [{}]", hostname, dto.getId());
return Optional.empty();
}
}
}To determine which blocking strategy to use, we use environment variables.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.env.Environment;
import org.springframework.stereotype.Component;
@Component
public class LockFactory {
private static final String REDIS = "redis";
private static final String CONSUL = "consul";
private static final String LOCK_TOOL = "lockTool";
private final LockHandler<CustomRedisLock> redisLock;
private final LockHandler<CustomConsulLock> consulLock;
private final Environment env;
@Autowired
public LockFactory(LockHandler<CustomRedisLock> redisLock, LockHandler<CustomConsulLock> consulLock, Environment env) {
this.redisLock = redisLock;
this.consulLock = consulLock;
this.env = env;
}
@SuppressWarnings("unchecked")
public <T extends FutureLock> LockHandler<T> getLockHandler(){
if ( env.getRequiredProperty(LOCK_TOOL).equalsIgnoreCase(CONSUL) ){
return (LockHandler<T>) consulLock;
} else if ( env.getRequiredProperty(LOCK_TOOL).equalsIgnoreCase(REDIS) ){
return (LockHandler<T>) redisLock;
} else {
throw new IllegalStateException("Unable to get Lock Tool");
}
}
}Stats:
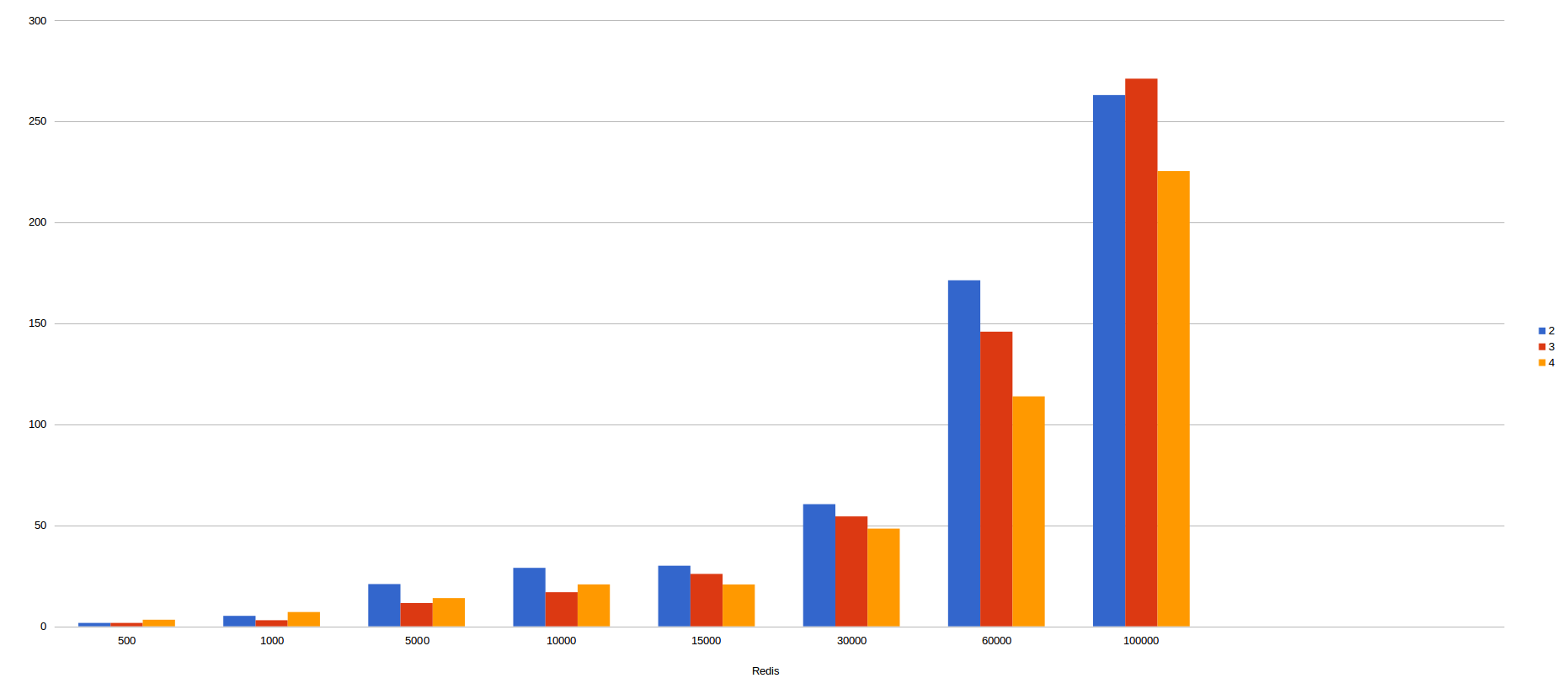
To determine the performance offered by both mechanism, I have been doing multiple benchmarcks with several executions, containers and number of messasges.
In the following pictures, we could see the results obtained by several executions in this scenarios visualized as diagrams:
- Redis.
- Redis with kafka batch mode.
- Consul with kafka batch mode.
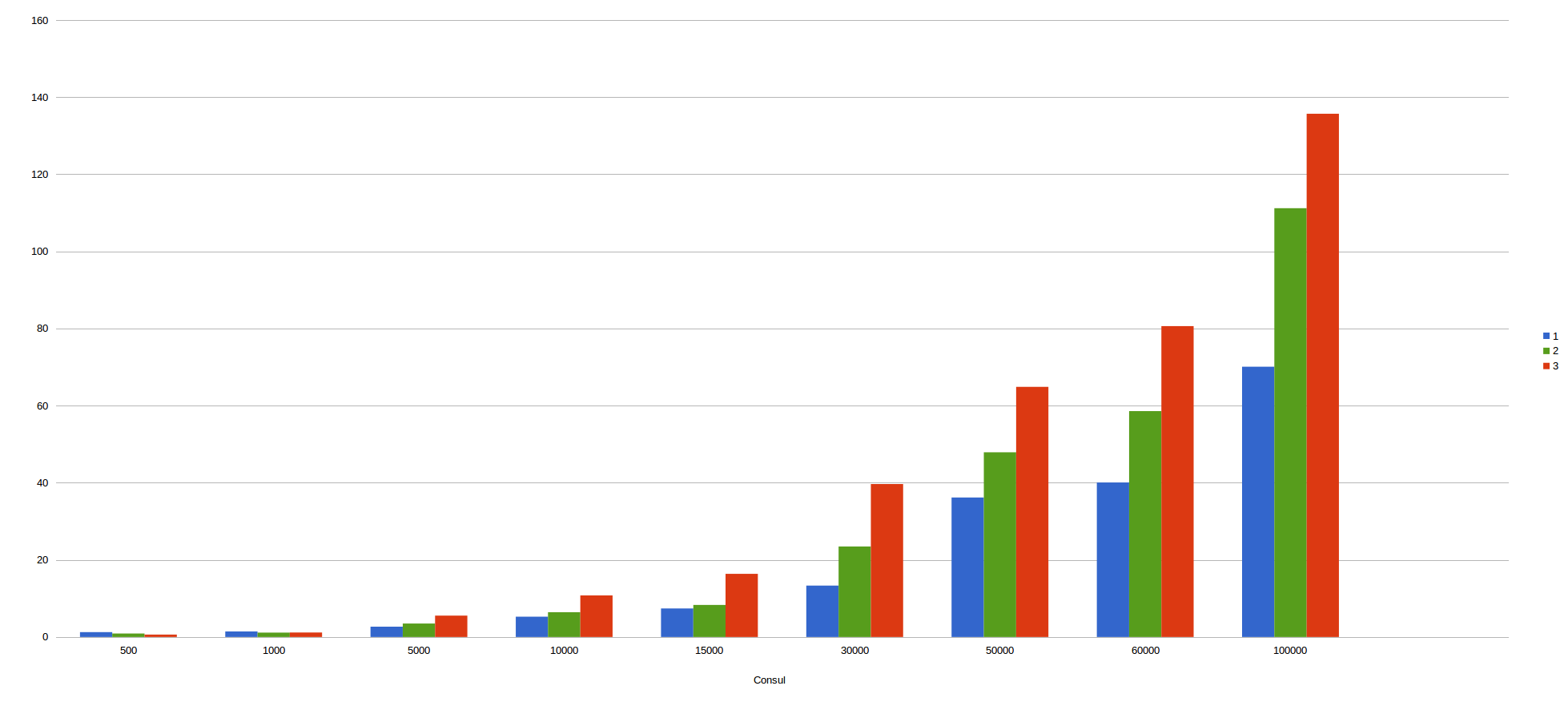
In the X axis, we can see the number of messages sent to kafka and in the Y axis we can see the total time spent in consuming all messages. The different colours represent the number of containers used in the benchmarcking.
Redis lock:
Redis lock with kafka batch mode:
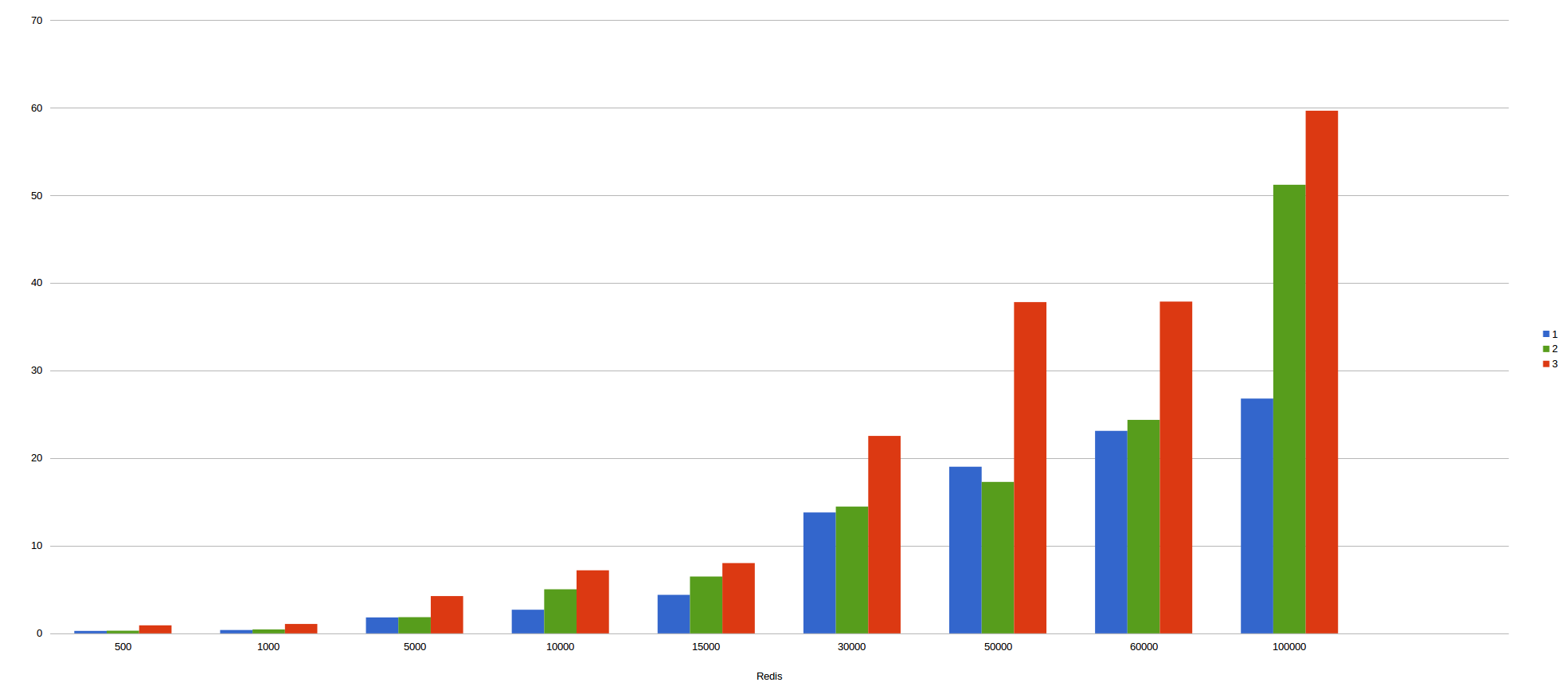
Consul lock with kafka batch mode:
Conclusions:
In my humble opinion, we can infer kafka batch mode is faster than non batch mode since the different is incredibly big, reaching differences of more than 30 seconds as for example in 30.000 messages.
As for which is faster, we can also conclude that redis is faster than consul due to the results obtained. For example, 50.000 messages are consumed in redis in less than 20 seconds, meanwhile, Consul took about 40 seconds, double than redis. With 100.000 messages ocurrs the same. Redis wins with only 25 seconds approximately, nevertheless consul took more than 60 seconds, problematic times for real time applications.
As a curiosity, with kafka batch mode, the more container we use, the more time we took since when increasing the containers, we increase the requests to our infrastructure and therefore the latency and collisions. However, as we persist a set of data instead of a single data, we substantially improve the times used thanks to mongo and its way of persisting large collections of data.
The full source code for this article is available over on GitHub.