
CQRS with Kafka Streams
1. Introduction
Last September, my coworker Iván Gutiérrez and me, spoke to our cowokers how to implement Event sourcing with Kafka and in this talk, I developed a demo with the goal of strengthen the theoretical concepts. In this demo, I developed a Kafka Stream that reads the tweets containing “Java” word from Twitter, group tweets by username and select the tweet with the most likes. The pipeline ends sending the recolected information to PostgreSQL
As we have received positive feedback and we have learned a lot of things, I want to share this demo in order to it will be available to anyone who wants to take a look.
The demo was divided into 5 steps.
2. Implementation
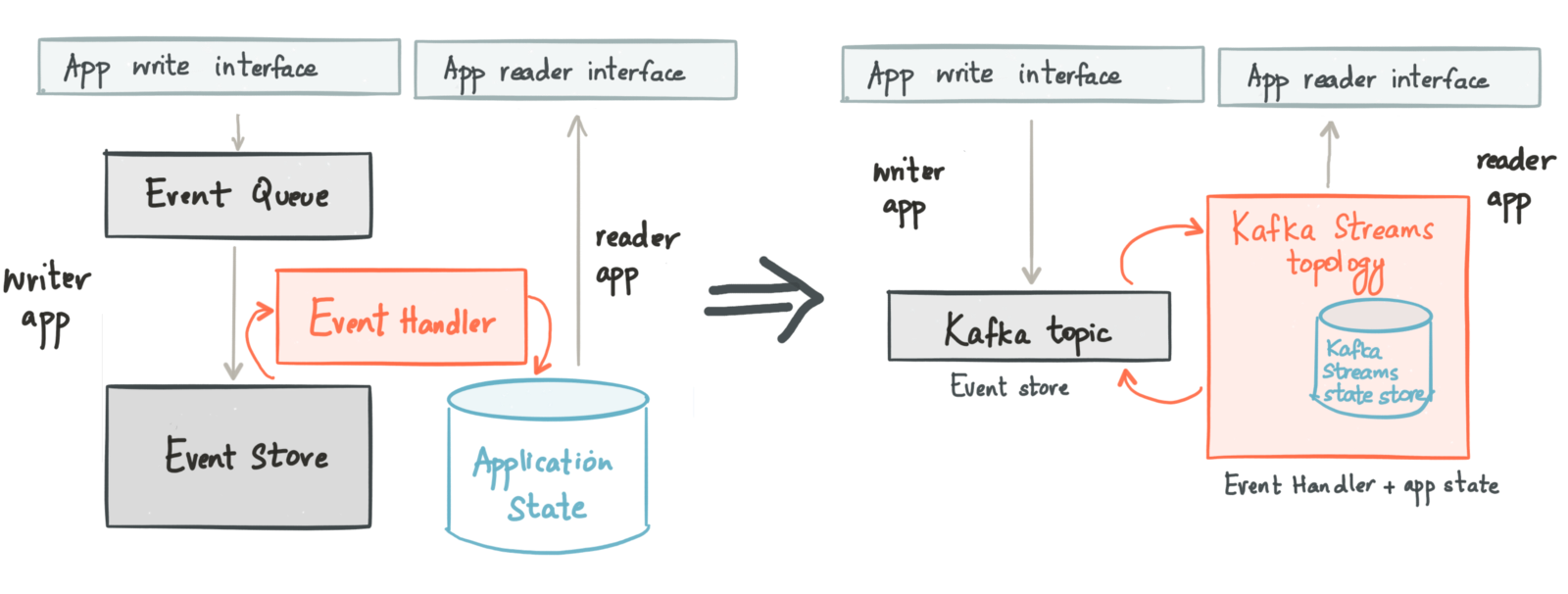
The demo is an implementaiton of the CQRS pattern based on Kafka and Kafka Streams. As we can see in the main image, Kafka is able of decoupling read (Query) and write (Command) operations, which helps us to develop event sourcing applications faster.
The Stack
The whole stack has been implemented in Docker for its simplicity when integrating several tools and for its isolation level. The stack is composed of
version: '3.1'
services:
#############
# Kafka
#############
zookeeper:
image: confluentinc/cp-zookeeper
container_name: zookeeper
network_mode: host
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka
container_name: kafka
network_mode: host
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_ZOOKEEPER_CONNECT: localhost:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 # We have only 1 broker, so offsets topic can only have one replication factor.
connect:
image: confluentinc/cp-kafka-connect
container_name: kafka-connect
network_mode: host
ports:
- "8083:8083"
depends_on:
- zookeeper
- kafka
volumes:
- $PWD/connect-plugins:/etc/kafka-connect/jars # in this volume is located the postgre driver.
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka:9092
CONNECT_REST_PORT: 8083 # Kafka connect creates an endpoint in order to add connectors
CONNECT_REST_ADVERTISED_HOST_NAME: "kafka-connect"
CONNECT_GROUP_ID: kafka-connect
CONNECT_ZOOKEEPER_CONNECT: zookeeper:2181
CONNECT_CONFIG_STORAGE_TOPIC: kafka-connect-config
CONNECT_OFFSET_STORAGE_TOPIC: kafka-connect-offsets
CONNECT_STATUS_STORAGE_TOPIC: kafka-connect-status
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1 # We have only 1 broker, so we can only have 1 replication factor.
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: "org.apache.kafka.connect.storage.StringConverter" # We receive a string as key and a json as value
CONNECT_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.storage.StringConverter"
CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_PLUGIN_PATH: /usr/share/java,/etc/kafka-connect/jars
#############
# PostgreSQL
#############
db:
container_name: postgresql
network_mode: host
image: postgres
restart: always
ports:
- "5432:5432"
environment:
POSTGRES_DB: influencers
POSTGRES_USER: user
POSTGRES_PASSWORD: 1234The above docker-compose file contains all tools involved in this demo:
- Zookeper: Inseparable partner of kafka.
- Kafka: The main actor. You need to set zookeeper ip. You can see all proficiencies in the provided slides above.
- Kafka Connector: One of the 4 main Kafka core API. It’s in charge of reading records of a provided topic and inserting them into PostgreSQL.
- PostgreSQL: SQL Database.
Producer
It’s the writer app. This piece of our infrastructure is in charge of read the tweets containing “Java” word from Twitter and send them to Kafka.
The following code has two sections: Twitter Stream and Kafka Producer.
Twitter Stream: Create a data stream of tweets. You can add a FilterQuery if you want to filter the stream before consuption. You need credentials for accesing to Twitter API. Kafka Producer: It sends records to Kafka. In our demo, it sends records without key to the ‘tweets’ topic.
@SpringBootApplication
@Slf4j
public class DemoTwitterKafkaProducerApplication {
public static void main(String[] args) {
// Kafka config
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); //Kafka cluster hosts.
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "demo-twitter-kafka-application-producer"); // Group id
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<>(properties);
// Twitter Stream
final TwitterStream twitterStream = new TwitterStreamFactory().getInstance();
final StatusListener listener = new StatusListener() {
public void onStatus(Status status) {
final long likes = getLikes(status);
final String tweet = status.getText();
final String content = status.getUser().getName() + "::::" + tweet + "::::" + likes;
log.info(content);
producer.send(new ProducerRecord<>("tweets", content));
}
//Some methods have been omitted for simplicity.
private long getLikes(Status status) {
return status.getRetweetedStatus() != null ? status.getRetweetedStatus().getFavoriteCount() : 0; // Likes can be null.
}
};
twitterStream.addListener(listener);
final FilterQuery tweetFilterQuery = new FilterQuery();
tweetFilterQuery.track(new String[] { "Java" });
twitterStream.filter(tweetFilterQuery);
SpringApplication.run(DemoTwitterKafkaProducerApplication.class, args);
Runtime.getRuntime().addShutdownHook(new Thread(() -> producer.close())); //Kafka producer should close when application finishes.
}
}This app is a Spring Boot application.
Kafka Stream
The main piece of our infrastructure is in charge of read the tweets from ‘tweets’ topics, group them by username, count tweets, extract the most liked tweet and send them to the ‘influencers’ topic.
Let’s focus on the two most important methods of the next block of code:
- stream method: Kafka Stream Java API follow the same nomenclature that the Java 8 Stream API. The first operation performed in the pipeline is to select the key since each time the key changes, a re-partition operation is performed in the topic. So, we should change the key as less as possible. Then, we have to calculate the tweet that most likes has accumulated. and as this operation is a statefull operation, we need to perform an aggregation. The aggregation operation will be detailed in the following item. Finally, we need to send the records to the output topic called ‘influencers’. For this task we need to map Influencer class to InfluencerJsonSchema class and then, use
tomethod. InfluencerJsonSchema class will be explained in Kafka Connector section. Peek method is used for debugging purposes. - aggregateInfoToInfluencer method: This is a statefull operation. Receives three args: the username, the raw tweet from the topic and the previous stored Influencer. Add one to the tweet counter and compare the likes with the tweet that more likes had. Returns a new instance of the Influecer class in order to mantain immutability.
@Configuration
@EnableKafkaStreams
static class KafkaConsumerConfiguration {
final Serde<Influencer> jsonSerde = new JsonSerde<>(Influencer.class);
final Materialized<String, Influencer, KeyValueStore<Bytes, byte[]>> materialized = Materialized.<String, Influencer, KeyValueStore<Bytes, byte[]>>as("aggregation-tweets-by-likes").withValueSerde(jsonSerde);
@Bean
KStream<String, String> stream(StreamsBuilder streamBuilder){
final KStream<String, String> stream = streamBuilder.stream("tweets");
stream
.selectKey(( key , value ) -> String.valueOf(value.split("::::")[0]))
.groupByKey()
.aggregate(Influencer::init, this::aggregateInfoToInfluencer, materialized)
.mapValues(InfluencerJsonSchema::new)
.toStream()
.peek( (username, jsonSchema) -> log.info("Sending a new tweet from user: {}", username))
.to("influencers", Produced.with(Serdes.String(), new JsonSerde<>(InfluencerJsonSchema.class)));
return stream;
}
private Influencer aggregateInfoToInfluencer(String username, String tweet, Influencer influencer) {
final long likes = Long.valueOf(tweet.split("::::")[2]);
if ( likes >= influencer.getLikes() ) {
return new Influencer(influencer.getTweets()+1, username, String.valueOf(tweet.split("::::")[1]), likes);
} else {
return new Influencer(influencer.getTweets()+1, username, influencer.getContent(), influencer.getLikes());
}
}
@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)
public StreamsConfig kStreamsConfigs(KafkaProperties kafkaProperties) {
Map<String, Object> props = new HashMap<>();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "demo-twitter-kafka-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getBootstrapServers());
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
return new StreamsConfig(props);
}
}@EnableKafkaStreams annotation and kStreamsConfigs method are the responsible of integrate the Kafka Stream API with Spring Framework. Further information of this integration is provided here
In the above block of code is mentioned Influencer class and in order to facilitate the read, the code of Influencer class is provided here:
@RequiredArgsConstructor
@Getter
public static class Influencer {
final long tweets;
final String username;
final String content;
final long likes;
static Influencer init() {
return new Influencer(0, "","", 0);
}
@JsonCreator
static Influencer fromJson(@JsonProperty("tweets") long tweetCounts, @JsonProperty("username") String username, @JsonProperty("content") String content, @JsonProperty("likes") long likes) {
return new Influencer(tweetCounts, username, content, likes);
}
}fromJson method is mandatory due to serialization proccess used by Kafka Stream. See Kafka Stream Serde if you want to know more about this topic.
This app is a Spring Boot application.
Kafka Connector
Once we have fed our topic ‘influencers’, we have to persist the data to Postgre. For this task, Kafka provide a powerful API called Kafka Connect. Confluent, the company created by Apache Kafka’s developers, has developed several connectors for many third-party tools. For JDBC, exits two connectors: source and sink. Source connectors reads data from jdbc drivers and send data to Kafka. Sink connectors reads data from Kafka and send it to jdbc driver.
We are going to use a JDBC Sink connector and this connector needs the schema information in order to map topic records into sql records. In our demo, the schema is provided in the topic record. For that reason, we have to map from Influecer class to InfluencerJsonSchema class in our data pipeline.
In the following code, you can see how the schema will be sent. If you want to see how is the result in json format you can see the provided gist.
/**
* https://gist.github.com/rmoff/2b922fd1f9baf3ba1d66b98e9dd7b364
*
*/
@Getter
public class InfluencerJsonSchema {
Schema schema;
Influencer payload;
InfluencerJsonSchema(long tweetCounts, String username, String content, long likes) {
this.payload = new Influencer(tweetCounts, username, content, likes);
Field fieldTweetCounts = Field.builder().field("tweets").type("int64").build();
Field fieldContent = Field.builder().field("content").type("string").build();
Field fieldUsername = Field.builder().field("username").type("string").build();
Field fieldLikes = Field.builder().field("likes").type("int64").build();
this.schema = new Schema("struct", Arrays.asList(fieldUsername,fieldContent,fieldLikes,fieldTweetCounts));
}
public InfluencerJsonSchema(Influencer influencer) {
this(influencer.getTweets(),influencer.getUsername(),influencer.getContent(),influencer.getLikes());
}
@Getter
@AllArgsConstructor
static class Schema {
String type;
List<Field> fields;
}
@Getter
@Builder
static class Field {
String type;
String field;
}
}Then, we need to configure our Kafka connector. Source topic, destination table, primary key or url connection should be provided. Special mention for the field ‘insert.mode’. We use ‘upsert’ mode due to the primary key is the username so the records will be inserted or updated depending on whether the user has been persited before or not.
{
"name": "jdbc-sink",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "influencers",
"table.name.format": "influencer",
"connection.url": "jdbc:postgresql://postgresql:5432/influencers?user=user&password=1234",
"auto.create": "true",
"insert.mode": "upsert",
"pk.fields": "username",
"pk.mode": "record_key"
}
}The above json code has been stored into a file in order to have a follow-up of it
Once we have developed the connector, we have to add the connector to our Kafka Connector container and this can be performed with a simple curl.
foo@bar:~$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @connect-plugins/jdbc-sink.json
Reader App
We have developed a simple Spring Boot applications to read inserted records in Postgre. This app is very simple and the code will be skipped of this post since it does not matter.
Attached a screenshot of the UI in order to view the results.
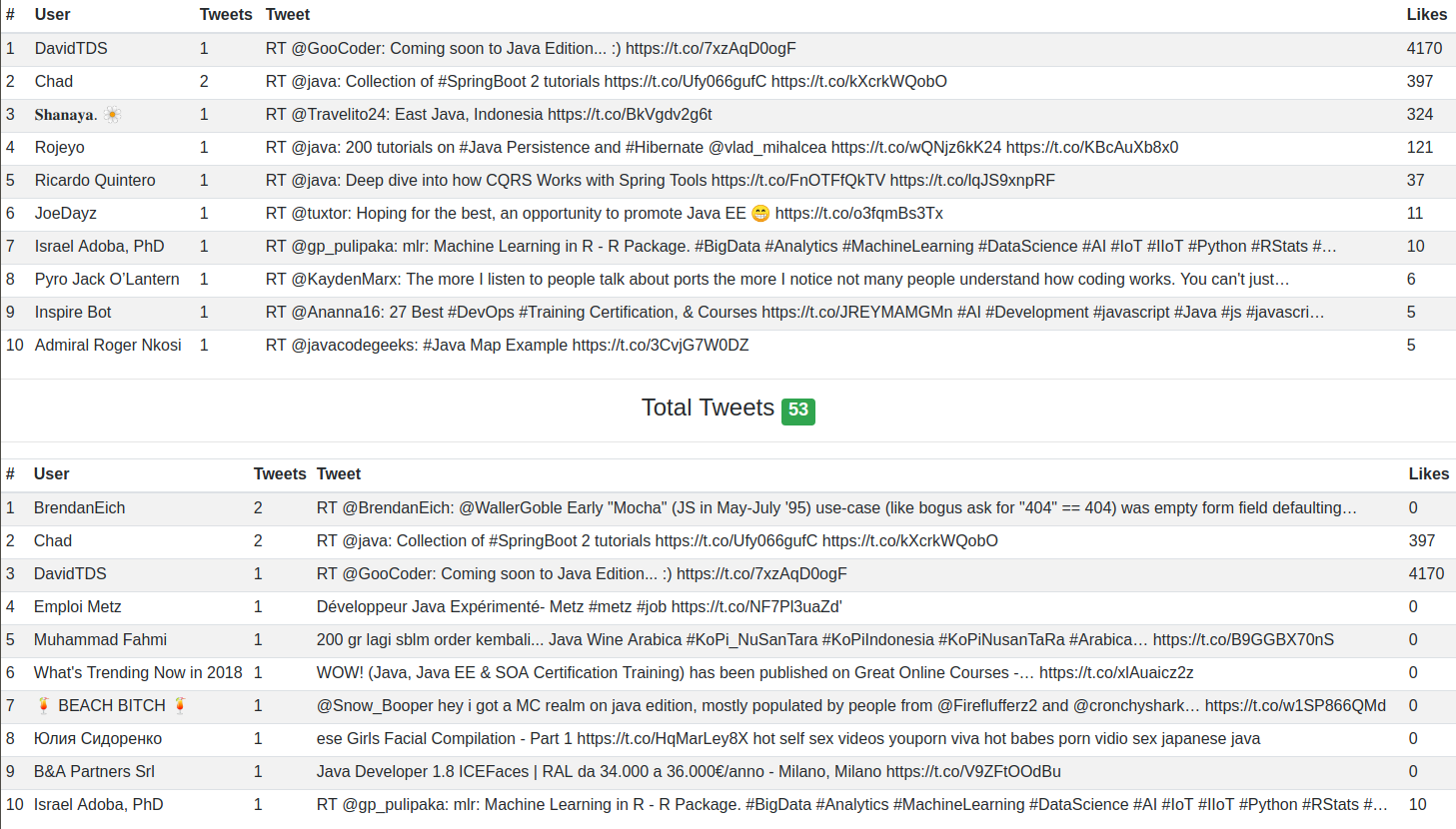
If you want to see the code, is available in Github
3. How to run
If you want to run the demo you have to execute the following commands.
-
foo@bar:~$ docker-compose up -
foo@bar:~$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @connect-plugins/jdbc-sink.json -
foo@bar:~$ mvn clean spring-boot:run -pl producer -
foo@bar:~$ mvn clean spring-boot:run -pl consumer -
foo@bar:~$ mvn clean spring-boot:run -pl reader
4. Conclusion
This demo show us a great example of a CQRS implementation and how easy it’s to implement this pattern with Kafka.
In my humble opinion, Kafka Stream is the most powerful API of Kafka since provide a simple API with awesome features that abstracts you from all the necessary implementations to consume records from Kafka and allows you to focus on developing robust pipelines for managing large data flows.
Besides, Spring Framework provides an extra layer of abstraction that allow us to integrate Kafka with Spring Boot applications.
The full source code for this article is available over on GitHub.